Speed up C++ — more is less
I have written two different versions of implementation for the same program. I ran perf profiling and obtained # instructions to run the…
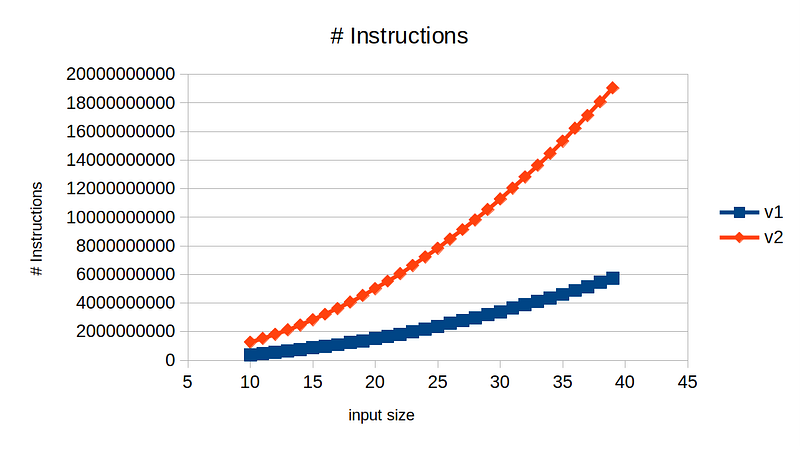
Looking at the plot above, we can see implementation v1 is much more efficient than v2, requiring 3x fewer instructions at input size of 40. Can we conclude v1 is the better implementation? Let’s take a look at the actual runtime between these two versions.
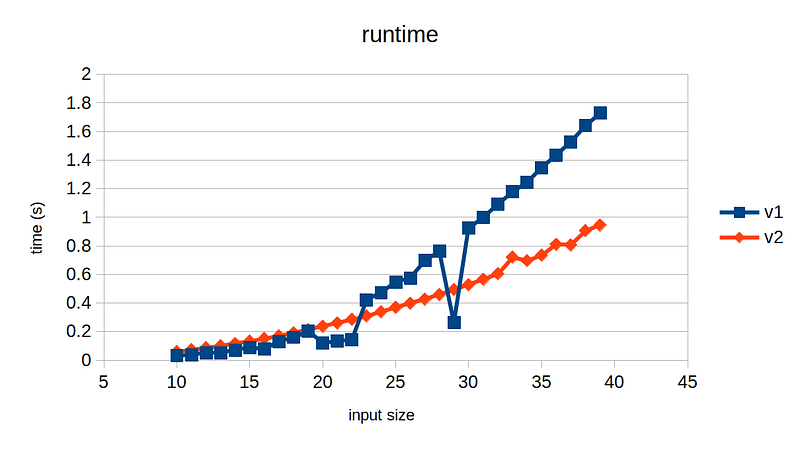
No, the legend is not reversed; it’s correct. Implementation v2 — that requires 3x more instructions — runs almost 2x faster than v1 for input size of 40. In fact, v1 runs slightly faster than v2 up until around input size of 22, and suddenly its runtime spikes, except at input size 29. Could this be just noise in the measurement?
To understand this better, we need to have a look at another profiling measurement plot: # branch misses
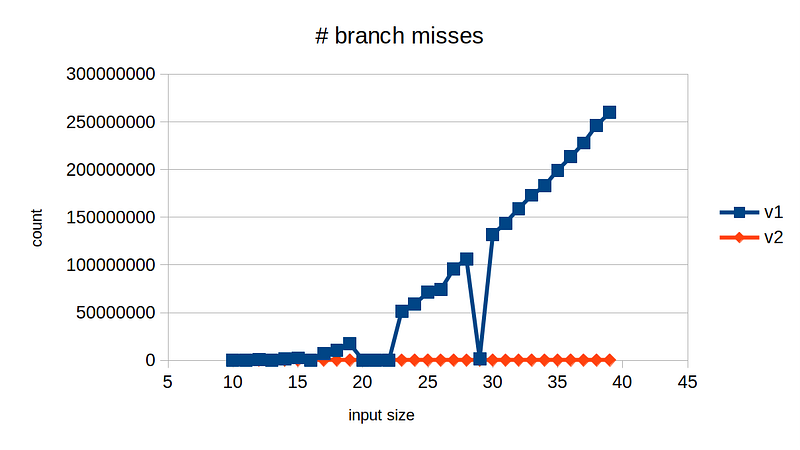
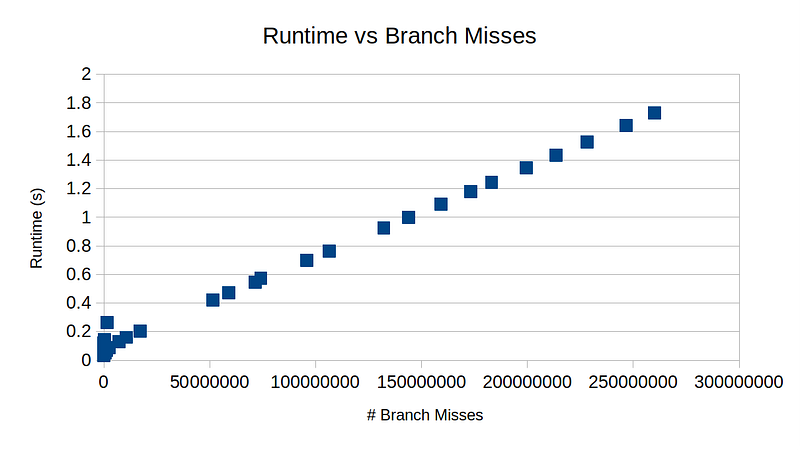
Hopefully now it must be apparent. The runtime is very closely aligned with the # branch misses. This is expected because branch misses are very expensive! Below is the plot of branch misses vs runtime for v1. They are in almost perfect linear relationship.
Now, let’s take a look at the code. The hottest part of the program is just a one-liner — given two optional values and a cumulative sum, add their product if they both contain values; if not, subtract 1.
// x, y are of type std::optional<int64_t>
// result is of type int64_t
result += bool(x) && bool(y) ? *x * *y : -1;
Assuming it is a random chance whether x and y contains a value, the branch misses percentage will be quite high, like more than 10%, resulting in significant slow down of the program.
5698537338 instructions
339562632 cache-references
4778539 cache-misses # 1.407 % of all cache refs
1518247881 branches
259675543 branch-misses # 17.10% of all branches
1.729146459 seconds time elapsed
1.724926000 seconds user
0.003992000 seconds sys
What is the fix? How does v2 completely removes branch misses? By getting rid of the conditional statement.
- result += bool(x) && bool(y) ? *x * *y : -1;
+ i64 branches[] = {-1, *x * *y};
+ result += branches[bool(x) && bool(y)];
That is, calculate the product of x and y regardless of whether the values are there or not, and choose either the product or -1 based on the predicate bool(x) && bool(y). We treat the predicate as boolean value, which is then cast as an index 0 or 1. We are doing more work now, since we are calculating the product of x and y every time. In fact, half of the time the values are just some garbage and we would eventually discard it because we will choose index 0. The point is that we got rid of the conditional statement by preparing for both scenarios, resulting in as much as 3x more instructions but more importantly 2x runtime reduction!
As always, you can find the source code here — I have the Rust-version of the same technique as well.
To learn more about this topic:
- Branchless Programming in C++ — Fedor Pikus — CppCon 2021 [link]
- https://stackoverflow.com/questions/11227809/why-is-processing-a-sorted-array-faster-than-processing-an-unsorted-array
- https://en.algorithmica.org/hpc/pipelining/branching/
Update
I realized that bool(x) && bool(y) statement is not actually branchless, since it short-circuits conditioned on bool(x). To be truly branchless, it needs to be bitwise-and, i.e., bool(x) & bool(y) instead. However, && runs faster on my benchmark, so I will leave it with &&. At least for the program I wrote, bool(x) is quite predictable most of the time, as x is fixed for the outer loop on y.