Curse of Dimensionality in Vector Search
With advancement in deep learning, everything has changed. In the heart of deep learning models is dense embedding vectors. In the deep learning models, everything is represented as a dense embedding vector. To find a similar picture or a relevant document from a deep model, we need to do a vector search, either exact or approximate.
Vector search is to find a vector x from the database xs for a given query vector q such that the distance function f(q,x) is minimum. For simplicity, let’s assume the distance function of Euclidean distance f(q,x) = norm2(q — x).
Brute-force vector search has time complexity of O(nd) where n is the number of vectors in the database and d is the dimensionality of the embedding vector. For a large number of n, brute-force search is not practical.
We can sacrifice the accuracy or recall of the vector search for faster runtime. A simple method is to partition the database vectors xs into, say m non-overlapping regions. When a query q comes in, we find the partition that contains q and do vector-search only within the corresponding partition. This would reduce our runtime proportional to the number of partitions. Of course, there is a chance that the target vector may not be in the partition, so the recall rate will drop. The idea is to be able to choose the correct partition with probability greater than by chance.
Below is a plot of recall at different dimensions and different number of clusters. More specifically, the x-axis shows the dimensionality of the vector space and y-axis shows the recall rate of finding the target vector in the region that contains the query.
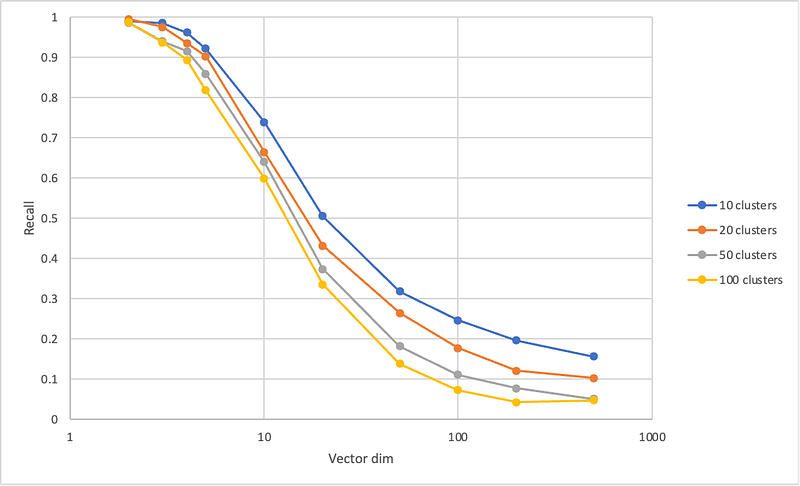
In the low-dimensionality regime, we observe that the recall rate is much higher than that by chance. For example, the recall with 100 clusters at 2-dimension is very close to 100%. That is, we can effectively reduce our search time by 100x and still achieve almost unity recall. At 10-dimension, the recall drops to 60%, which is still 60x of the pure chance. However, this favor in probability quickly diminishes as the number of dimension grows larger. At 100-dimension, for example, the recall-rate is shy of 10%.
By the way, this method of finding an approximate nearest neighbor (ANN) I just described is the basic algorithm behind Faiss-IVF. All the source code is published to this repo.