Speed up BERT — Tokenizer
BERT (Bidirectional Encoder Representations from Transformers) is a popular pre-trained language model that has been widely used in natural language processing (NLP) tasks. BERT models require a special type of tokenization that separates words and sub-words into smaller units called “wordpieces”. This process is essential for BERT models to accurately represent the meaning of a given text. In this blog, we will compare the performance of three libraries that implement BERT tokenizers: HuggingFace, TensorFlow, and BlingFire.
The BERT subwords have been extracted with wordpiece algorithm, which is similar to, but slightly different from another popular algorithm Byte-Pair-Encoding (BPE). Today, I want to focus on what happens after the subwords are extracted. If you are interested in how the tokenizer is trained, here is an excellent article from HuggingFace.
BERT Tokenizer takes in the vocabulary, does some preprocessing such as normalization, and tokenizes by reading the string from left to right, applying longest prefix match with the vocabulary. This is different from how BPE tokenizes, which repetitively merges a pair of two adjacent tokens in the order of merge-priority from the entire string. Again, here is an excellent article on how BPE works.
If you are experimenting with BERT, you will probably end up using HuggingFace or TensorFlow. HuggingFace is a popular open-source library for NLP models, including BERT. TensorFlow is an open-source machine learning framework that also provides a BERT tokenizer. Personally, I find HuggingFace library much easier to use compared to TensorFlow. BlingFire is open-source library that supports different tokenization schemes using a finite-automaton (state machine).
Today, I want to compare the tokenization speed from these three libraries for BERT base uncased. HuggingFace and TensorFlow implement two versions of BERT tokenizer: a slower one and a faster one. I will only experiment with the faster implementation from each library. HuggingFace’s faster version is called BertTokenizerFast, which can be easily instantiated with
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
TensorFlow’s faster version is called FastBertTokenizer. Its instantiation is a bit tricky
import tensorflow_text as tf_text
tokenizer = tf_text.FastBertTokenizer(vocab, lower_case_nfd_strip_accents=True)
where vocab is a list of wordpieces. You can find the model’s vocab file here. Finally, BlingFire’s BERT tokenizer can be instantiated with
import os
import blingfire
tokenizer = blingfire.load_model(os.path.join(os.path.dirname(blingfire.__file__), "bert_base_tok.bin"))
What I’m mainly interested is the end-to-end performance among the three. I tokenized 1M lines of wikitext dataset with the BERT tokenizer from each library on a single-thread. Below is the result.
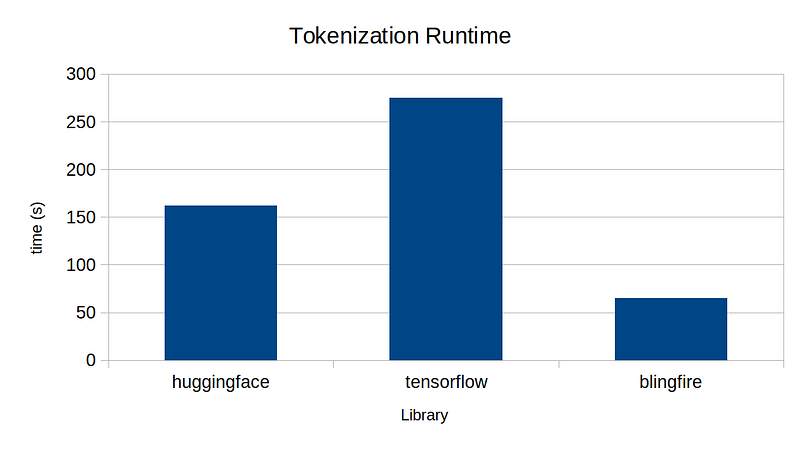
One thing that may surprise you is how long it takes to tokenize. It takes longer than 1 minute to tokenize just 1M lines! Given that large language models are typically trained with trillions of tokens, you can imagine how much of computation is required just to tokenize the training dataset! We tend to forget this because model training/inference is the main bottleneck.
In any case, my experiment shows BlingFire’s implementation is the fastest by a large margin, followed by HuggingFace, followed by TensorFlow. This was particularly interesting because Google has recently published a paper, boasting its novel algorithm with a claim that it is 8x faster than HuggingFace. Somehow, I was not able to reproduce the result — if anyone knows what I’m missing here, please let me know!
In theory, the all BERT tokenizers should produce exactly the same sequence of tokens. Unfortunately, this was not the case. Below shows token-level parities among the three libraries I tested.
HuggingFace to TensorFlow: 99.981%
HuggingFace to BlingFire: 99.996%
TensorFlow to BlingFire: 99.978%
HuggingFace and BlingFire produced much higher parity compared to TensorFlow. Though the parities are not 100%, I suppose in most practical applications the three tokenizers can be interchangeable without much issue.
In conclusion, I recommend BlingFire’s tokenization library. Though this is not as popular as other libraries, it can save you CPU resources quite a bit. If you want to run the experiment yourself, you can find the source code here.