Speed up GPT2 — tokenizer
Tokenization is an essential step in natural language processing that involves splitting text into smaller units called tokens, which can then be used for various tasks such as language modeling, text classification, and sentiment analysis. In this blog post, we’ll compare the tokenization speed of the GPT2 model using three different libraries: HuggingFace, BlingFire, and TikToken.
To instantiate GPT2 tokenizer with HuggingFace, we can do
from transformers import GPT2TokenizerFast
tokenizer = GPT2TokenizerFast.from_pretrained('gpt2')
With BlingFire, we do
import blingfire
tokenizer_handle = blingfire.load_model(os.path.join(os.path.dirname(blingfire.__file__), 'gpt2.bin'))
Lastly, with TikToken, we write
import tiktoken
tokenizer = tiktoken.encoding_for_model('gpt2')
For this benchmark, I used 1M lines of wikitext dataset. Below is the plot of the runtime result.
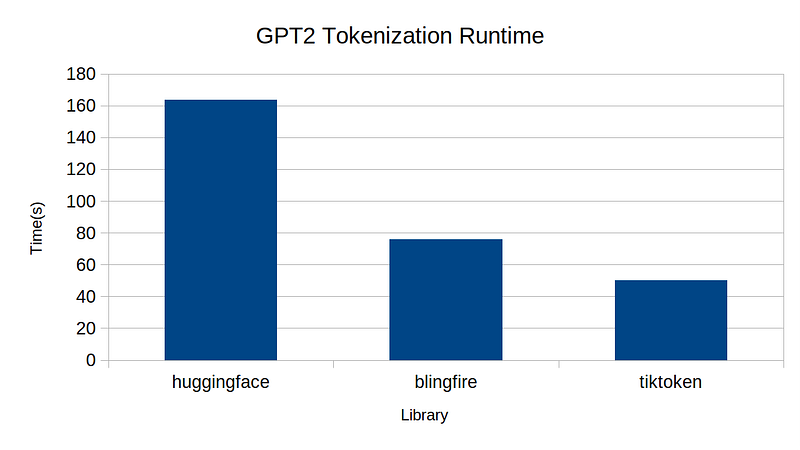
From the experiment, we can see TikToken’s implementation is the fastest, followed by BlingFire, followed by HuggingFace. This is not the whole story, however. I compared token-level parities between pairs among the three:
parity between HuggingFace vs BlingFire: 96.737%
parity between HuggingFace vs TikToken: 100%
parity between TikToken vs BlingFire: 96.737%
This tells me that HuggingFace and TikToken are 100% compatible, but BlingFire produces different results, probably enough to make difference during training or inference. I feel like maybe I am missing something here with BlingFire, but unfortunately I wasn’t able to find good documentation.
For those who want to run the benchmark, all the source code is uploaded here. If anyone knows why I have so much disparity between BlingFire and others, please let me know!