Speed up C++ — parallelize part 1
In the modern world, multicore processors are de facto standard. Even a credit-card sized $15 single-board computers are equipped with 4-cores. Utilizing n-cores in the processor can speed up your program by n times— at least in theory.
Writing a multi-threaded application is not an easy task. There is a steep curve to overcome, and debugging becomes 10x more difficult, having to deal with all kinds of issues rising from race conditions. Not only that, managing threads with low-level API, e.g., std::thread is just too plain painful.
Fortunately, there is a library that makes it so much easier. OpenMP is a library for parallel programming in shared-memory multiprocessing environments. It is an Application Programming Interface (API) that allows developers to write programs that can take advantage of the computational power of multiple cores and processors within a single computer. This library is well-supported by compilers (gcc, clang, msvc) and is portable, running on Linux, macOS, and Windows.
Most importantly, its APIs are easy and intuitive enough that you can focus on parallel design of your program rather than getting bogged down in the details of parallel programming implementation. With OpenMP, you can simply add a few compiler directives to your code, indicating which parts of the code should be executed in parallel, and the library takes care of the rest. This significantly reduces the amount of effort and time required to write parallel programs, making it an essential tool for developers who want to improve the performance of their applications without sacrificing code readability and maintainability.
So, let’s start off with a simple example. The easiest example is a simple for-loop that executes an expression that is on its own. Consider the following function that estimates the value of π — this is taken from exercise 2 of this great series on Introduction to OpenMP:
double estimate_pi_seq(uint64_t num_steps) {
auto delta = 1.0 / static_cast<double>(num_steps);
double pi = 0.0;
for (uint64_t step = 0; step < num_steps; ++step) {
auto x = delta * (static_cast<double>(step) + 0.5);
pi += 4.0 / (1 + x * x);
}
return pi * delta;
}
This function estimates the value of π by numerical integration of the function 4/(1+x^2) from 0 to 1. Evaluating the function with large num_steps gives pretty good approximation to π.
Now, let’s parallelize this function using OpenMP. Given that each calculation within the loop is independent, we can easily parallelize the code with parallel-for. In OpenMP, that can be written as
double estimate_pi_par(uint64_t num_steps) {
auto delta = 1.0 / static_cast<double>(num_steps);
double pi = 0.0;
#pragma omp parallel for default(none) shared(num_steps, delta) reduction(+:pi)
for (uint64_t step = 0; step < num_steps; ++step) {
auto x = delta * (static_cast<double>(step) + 0.5);
pi += 4.0 / (1 + x * x);
}
return pi * delta;
}
Maybe it is easier to show the diff between the two:
--- seq
+++ par
@@ -1,6 +1,7 @@
-double estimate_pi_seq(uint64_t num_steps) {
+double estimate_pi_par(uint64_t num_steps) {
auto delta = 1.0 / static_cast<double>(num_steps);
double pi = 0.0;
+#pragma omp parallel for default(none) shared(num_steps, delta) reduction(+:pi)
for (uint64_t step = 0; step < num_steps; ++step) {
auto x = delta * (static_cast<double>(step) + 0.5);
pi += 4.0 / (1 + x * x);
Essentially, we parallelize the code with a single line. That’s it. This line tells the compiler to use OpenMP and parallelize the for-loop. Here, shared() explicitly specifies which variables are shared across threads, and reduction() specifies which variable to be reduced from partial results. All other variables not specified are assumed to be private, i.e., can be accessed by its own thread only. With this single-liner, the compiler will do all the hard work for us and generate efficient parallelized implementation.
We do not even need to worry about low-level implementation to resolve race-condition with respect to pi variable — we explicitly specified this as a reduction variable, and OpenMP takes care of it based on our specification. Note that OpenMP is not a magic wand. It will not figure out which variables pose race-condition. It is the programmer’s responsibility to know which variables pose race-condition and need to ask OpenMP explicitly to take care of it.
Here’s the full source-code.
#include <iostream>
#include <omp.h>
#include <string>
using namespace std::string_literals;
double estimate_pi_seq(uint64_t num_steps) {
auto delta = 1.0 / static_cast<double>(num_steps);
double pi = 0.0;
for (uint64_t step = 0; step < num_steps; ++step) {
auto x = delta * (static_cast<double>(step) + 0.5);
pi += 4.0 / (1 + x * x);
}
return pi * delta;
}
double estimate_pi_par(uint64_t num_steps) {
auto delta = 1.0 / static_cast<double>(num_steps);
double pi = 0.0;
#pragma omp parallel for default(none) shared(num_steps, delta) reduction(+:pi)
for (uint64_t step = 0; step < num_steps; ++step) {
auto x = delta * (static_cast<double>(step) + 0.5);
pi += 4.0 / (1 + x * x);
}
return pi * delta;
}
int main(int argc, const char **argv) {
uint64_t num_steps = std::stoull(argv[1]);
auto calc_pi = [argv](uint64_t num_steps) {
return "seq"s == argv[2] ? estimate_pi_seq(num_steps) : estimate_pi_par(num_steps);
};
auto pi = calc_pi(num_steps);
std::cout << pi << "\n";
}
To compile, simply specify -fopenmp flag to the compiler. That’s it!
$ g++ -std=c++17 -O3 -fopenmp pi.cc -o pi
$ time ./pi 100000000 seq
3.14159
real 0m0.108s
user 0m0.108s
sys 0m0.000s
$ time ./pi 100000000 par
3.14159
real 0m0.028s
user 0m0.277s
sys 0m0.000s
By default, OpenMP tries to use as many (hyper)threads available in the system. You can explicitly specify maximum number of threads OpenMP can utilize with environment variable OMP_NUM_THREADS:
$ time OMP_NUM_THREADS=1 ./pi 100000000 par
3.14159
real 0m0.111s
user 0m0.111s
sys 0m0.000s
On my AMD Ryzen 5800H processor with 6 physical-cores and 12 hyer-threads, here is my speed up:
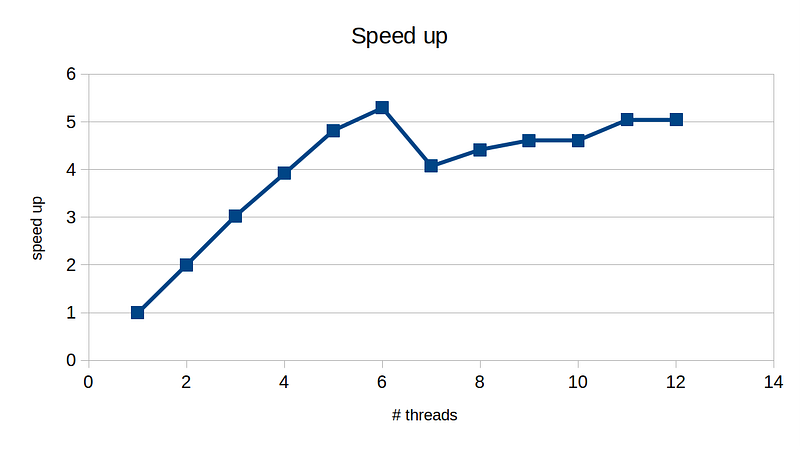
We can see pretty good speed up until 6 threads, which is equal to the # of physical cores, and then degradation when we utilize hyperthreads. For best performance, we would cap the number of threads to 6 in this case.
In conclusion, OpenMP is a powerful library that enables parallelization of our code with minimal effort. In the upcoming series, I will dive deeper with OpenMP.