OpenMP — section vs task
OpenMP has two similar but very different constructs section and task. Today, let’s talk about they differ with a simple example.
OpenMP’s section can be thought of as a static number of blocks of code to be executed in parallel. By static, I mean the number of blocks is to be fixed and known at compile time. On the other hand, task can be thought of as a way to break down into a dynamic number of blocks to be executed in parallel. By dynamic, I mean the number of blocks is not determined at compile time and depends on runtime.
With this, you can imagine that task is more powerful than section. In fact, section construct has been there since the very first version of OpenMP 1.0, whereas task was introduced 10-years later in OpenMP 3.0.
Let’s dive a little deeper with a concrete example — quicksort. I bet you are already familiar with quicksort, so let’s jump right into its serial implementation:
template <typename It> auto partition(It const first, It const last) {
auto pivot = *first;
auto mid = first;
for (auto it = last - 1; it > mid;) {
if (*it < pivot) {
std::iter_swap(it, ++mid);
} else {
--it;
}
}
std::iter_swap(first, mid);
return mid;
}
template <typename It> void quicksort_serial(It const first, It const last) {
auto distance = std::distance(first, last);
if (distance < 2)
return;
auto mid = partition(first, last);
quicksort_serial(first, mid);
quicksort_serial(mid + 1, last);
}
Now, let’s parallelize it with OpenMP’s section construct:
template <typename It>
void quicksort_par_sections(It const first, It const last) {
auto distance = std::distance(first, last);
if (distance < DISTANCE_THRESHOLD)
return quicksort_serial(first, last);
auto mid = partition(first, last);
#pragma omp parallel sections default(none) shared(first, mid, last)
{
#pragma omp section
quicksort_par_sections(first, mid);
#pragma omp section
quicksort_par_sections(mid + 1, last);
}
}
Here, DISTANCE_THRESHOLD is some fixed large number, say 100. We will revert back to the serial implementation if the number of elements in the partial array is less than this number — this is to reduce overhead in multithreading for a trivial task. Parallelizing with section was quite trivial. Now, let’s test its performance gain on multithreads:
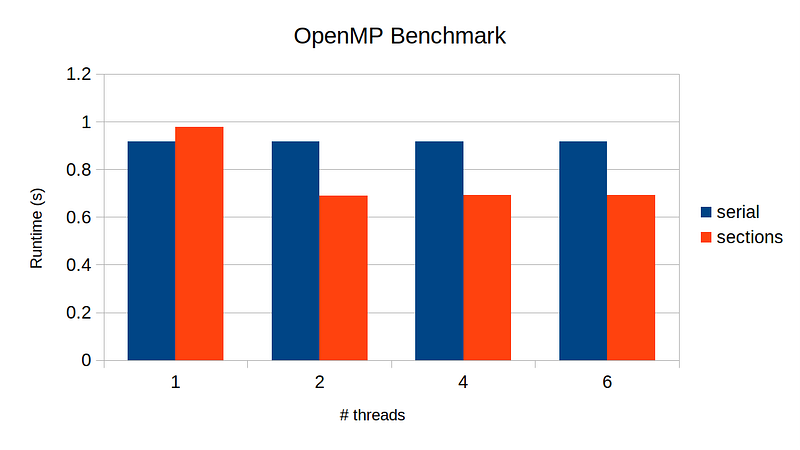
What is going on here? The speed up with 2–threads and upward is essentially identical! As I mentioned earlier, section works only with static number of parts to parallelize. In our example, that number is 2 — the left-half and the right-half. Moreover, there is no nesting-parallelization support out of the box. That is, our code will be executed by at most 2-threads concurrently, severely limiting the performance gain.
Now, let’s look into task construct. Below is parallel implementation using OpenMP’s task:
template <typename It>
void quicksort_par_tasks_helper(It const first, It const last) {
auto distance = std::distance(first, last);
if (distance < DISTANCE_THRESHOLD)
return quicksort_serial(first, last);
auto mid = partition(first, last);
#pragma omp task default(none) shared(first, mid)
quicksort_par_tasks_helper(first, mid);
#pragma omp task default(none) shared(mid, last)
quicksort_par_tasks_helper(mid + 1, last);
// this is absolute necessity!!!
// without it, this function returns
// before the recursive calls complete,
// invalidating the stack
#pragma omp taskwait
}
template <typename It> void quicksort_par_tasks(It first, It last) {
#pragma omp parallel default(none) shared(first, last)
{
// we are in the omp parallel region
// we want only one thread to be assinged for each task
#pragma omp single
quicksort_par_tasks_helper(first, last);
}
}
This is a bit trickier than section. Rather than me going over the code, I will direct you to really helpful resources I found: 1, 2, 3. Now, let’s run the benchmark:
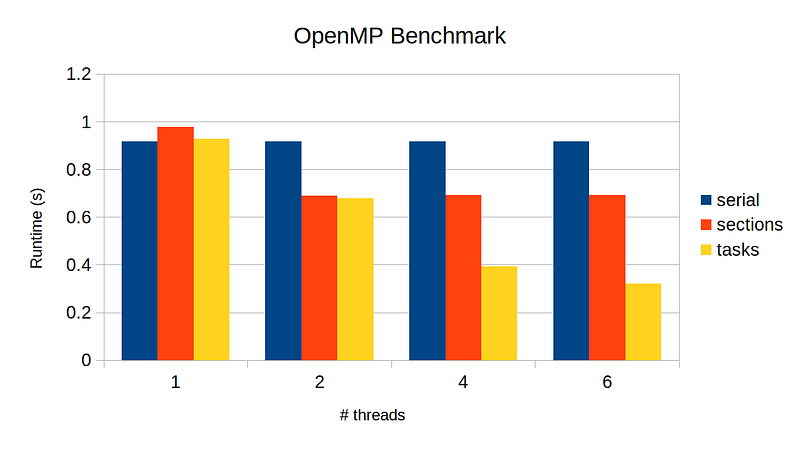
Finally, we see performance gain as we increase the number of threads, though the speed-up is not close to the ideal. We can at least tell from the plot that task does make use of all threads available, whereas section was only able to use 2-threads at a time.
If you are interested in running the program yourself, check out my repo with full source code.