Speed up OpenMP — remove unnecessary synchro
In the previous story, we explored how to parallelize quicksort algorithm using OpenMP’s section and task construct. In particular, we have observed that while section can utilize only two threads concurrently, we were able to get much better speed up with task.
Below is the recap of the quicksort runtime among three implementations: serial, section, and task. Though task runs the fastest, its speed up is not ideal. In this story, let’s see if we can further squeeze out the performance of our parallel implementation.
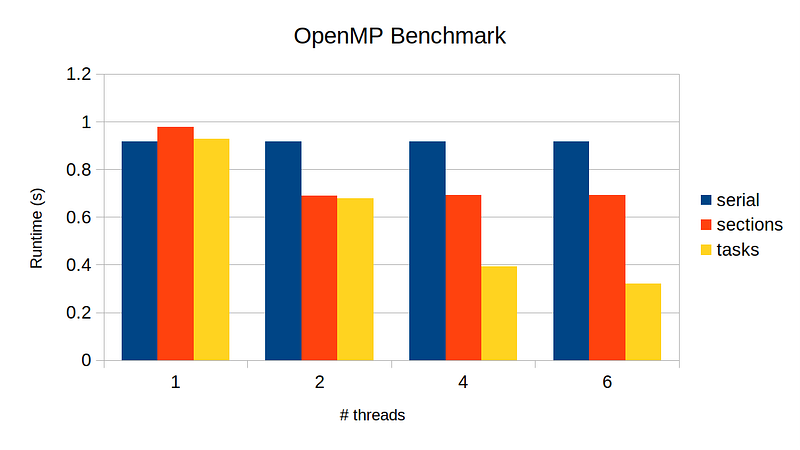
Let’s revisit our task-based parallel implementation.
template <typename It>
void quicksort_par_tasks_helper(It const first, It const last) {
auto distance = std::distance(first, last);
if (distance < DISTANCE_THRESHOLD)
return quicksort_serial(first, last);
auto mid = partition(first, last);
#pragma omp task default(none) shared(first, mid)
quicksort_par_tasks_helper(first, mid);
#pragma omp task default(none) shared(mid, last)
quicksort_par_tasks_helper(mid + 1, last);
// this is absolute necessity!!!
// without it, this function returns
// before the recursive calls complete,
// invalidating the stack
#pragma omp taskwait
}
template <typename It> void quicksort_par_tasks(It first, It last) {
#pragma omp parallel default(none) shared(first, last)
{
// we are in the omp parallel region
// we want only one thread to be assinged for each task
#pragma omp single
quicksort_par_tasks_helper(first, last);
}
}
Do you see anything that we may want to improve? If you have read my story on common pitfall with task construct, you may have noticed that first, mid, last variables are declared as shared, rather than firstprivate. As I mentioned in the story, variables in the task construct should most likely be firstprivate; otherwise it will most likely cause race condition, since the execution of the task may be deferred at a later time.
That is why I have omp taskwait construct at the end of the function — to prevent the function to return before the tasks are executed. Without this, as the comment suggests, the variables first, mid, last will be invalidated, as they are on the stack of the function.
This implementation works just fine, but this may not run as efficient. We have too many wait — one for each recursive function call. That is a lot of synchronization overhead. The reason we needed omp taskwait clause is due to race-condition of the shared variables. To prevent it, we can set firstprivate policy, and by doing so we release unnecessary synchronization overhead. Below is the improved implementation:
--- task
+++ task improved
@@ -1,27 +1,25 @@
template <typename It>
-void quicksort_par_tasks_helper(It const first, It const last)
+void quicksort_par_tasks2_helper(It const first, It const last)
{
auto distance = std::distance(first, last);
if (distance < DISTANCE_THRESHOLD)
return quicksort_serial(first, last);
auto mid = partition(first, last);
-#pragma omp task default(none) shared(first, mid)
+#pragma omp task default(none) firstprivate(first, mid)
quicksort_par_tasks_helper(first, mid);
-#pragma omp task default(none) shared(mid, last)
+#pragma omp task default(none) firstprivate(mid, last)
quicksort_par_tasks_helper(mid + 1, last);
-
-#pragma omp taskwait
}
template <typename It>
-void quicksort_par_tasks(It first, It last)
+void quicksort_par_tasks2(It first, It last)
{
#pragma omp parallel default(none) shared(first, last)
{
// we are in the omp parallel region
// we want only one thread to be assinged for each task
-#pragma omp single
- quicksort_par_tasks_helper(first, last);
+#pragma omp single nowait
+ quicksort_par_tasks2_helper(first, last);
}
}
I also added nowait clause for the omp single clause, since there is already an implicit barrier at the end of omp parallel region anyways. So, with these changes, let’s run and see how much faster our new implementation runs.
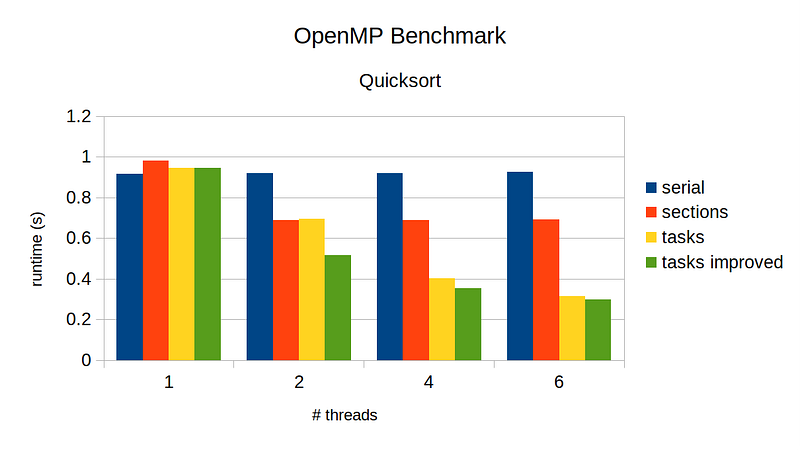
The green bars represent runtime with our improved implementation that removes unnecessary synchro overhead. We can see that the new implementation significantly improves performance, especially for the case of 2-threads.
Again, you can check out the full source code in here.