Rust— hash table part 3
In the previous stories, we wrote hash table data structure completely from scratch in Rust. Today, let’s write a test function to make sure our hash table behaves exactly the same as that of the standard library. Then, we will write simple benchmark tests to compare their performance.
As for the test, I will call five methods insert(), get(), get_mut(), remove(), and len() millions of times in random order with random key and values. For every iteration, I will compare the result with that obtained from the target, which is the standard library implementation. This test makes sure that the two implementations have exactly the same behavior.
use rand::distributions::*;
fn run_test() {
let mut map1 = rust_hashmap::HashMap::new(); // our implementation
let mut map2 = std::collections::HashMap::new(); // standard library implementation
let key_gen = Uniform::from(0..1000); // random key, value
let op_gen = Uniform::from(0..5); // operation selection
let mut rng = rand::thread_rng();
for _ in 0..10000000 {
let val = key_gen.sample(&mut rng);
let key = val;
match op_gen.sample(&mut rng) {
0 => {
// insert
assert_eq!(map1.insert(key, val), map2.insert(key, val));
}
1 => {
// get mut
assert_eq!(
map1.get_mut(&key).map(|x| {
*x += 1;
x
}),
map2.get_mut(&key).map(|x| {
*x += 1;
x
})
);
}
2 => {
assert_eq!(map1.get(&key), map2.get(&key));
}
3 => {
assert_eq!(map1.remove(&key), map2.remove(&key));
}
_ => {
assert_eq!(map1.len(), map2.len());
}
}
}
}
I ran the test multiple times, and the test has never had any failure. Next is to measure performance difference between the two. For that, I will write MapTrait that shares the common interface between the two, so that I can write a generic benchmark function.
fn run_bench_i64<M>()
where
M: MapTrait<i64, i64>,
{
let mut map = M::new();
let key_gen = Uniform::from(0..1000);
let op_gen = Uniform::from(0..4);
let mut rng = rand::thread_rng();
for _ in 0..10000000 {
let val = key_gen.sample(&mut rng);
let key = val;
match op_gen.sample(&mut rng) {
0 => {
// insert
map.insert(key, val);
}
1 => {
// get mut
map.get_mut(&key).map(|x| {
*x += 1;
x
});
}
2 => {
// get
map.get(&key);
}
3 => {
// remove
map.remove(&key);
}
_ => {}
}
}
}
Similar to the test function, this will repetitively run random operation with random key, value on the given hash table. Below shows runtime of this benchmark function on our custom implementation vs standard library implementation, compiled with optimization flag.
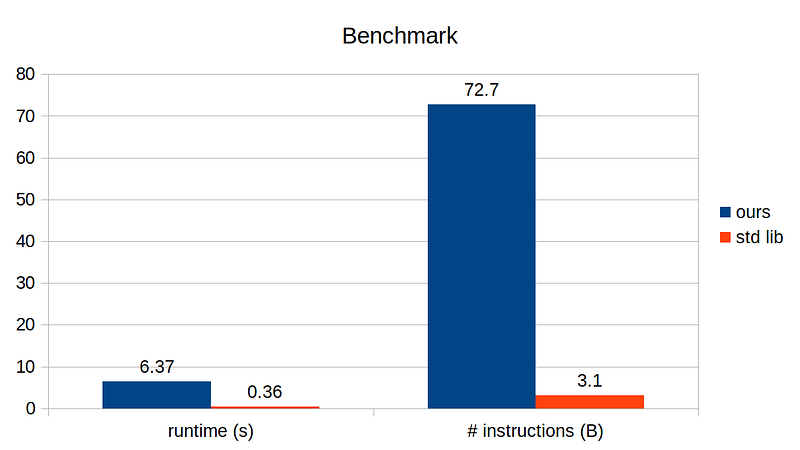
The difference is massive! Both the runtime difference and # instructions required to run the same benchmark test differs by 20x. What is going on?
When testing and benchmarking the program, there is one more metric we should consider: memory consumption.
We know that our hash table works as expected in terms of the behavior, but we do not know if it is efficiently using the system memory. The easiest way to measure memory consumption of a program is to run with gnu time and inspect its resident set size (RSS). This can be a bit tricky because on bash, for example, time is a built-in command. To explicitly run gnu time, one needs to type in the full path:
$ which time
/usr/bin/time
$ /usr/bin/time -v ./a.out 2>&1 | grep "Maximum resident"
Maximum resident set size (kbytes): 39396
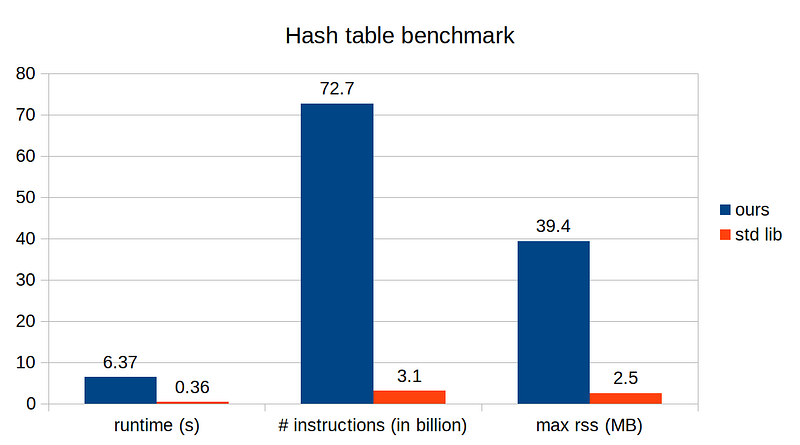
OK, we get the idea. Our implementation is somehow managing the memory very inefficiently, which is the main performance bottleneck. With this plot, I feel that we must revisit our resize() method to see what is going on. Indeed, the culprit is that we unconditionally double the array size even if there are barely no occupied entries. A more appropriate approach is to examine the occupied factor and decide whether to keep the array size or double it.
--- before
+++ after
+
+ fn occupied_factor(&self) -> f64 {
+ if self.xs.is_empty() {
+ 1.0
+ } else {
+ self.n_occupied as f64 / self.xs.len() as f64
+ }
+ }
+
fn resize(&mut self) {
- let new_size = max(64, self.xs.len() * 2);
+ let resize_factor = if self.occupied_factor() > 0.75 { 2 } else { 1 };
+ let new_size = max(64, self.xs.len() * resize_factor);
let mut new_table = Self {
xs: (0..new_size).map(|_| Entry::Vacant).collect(),
n_occupied: 0,
With this simple change, our implementation has improved more than 10x, and our implementation is quite comparable to the standard library’s!
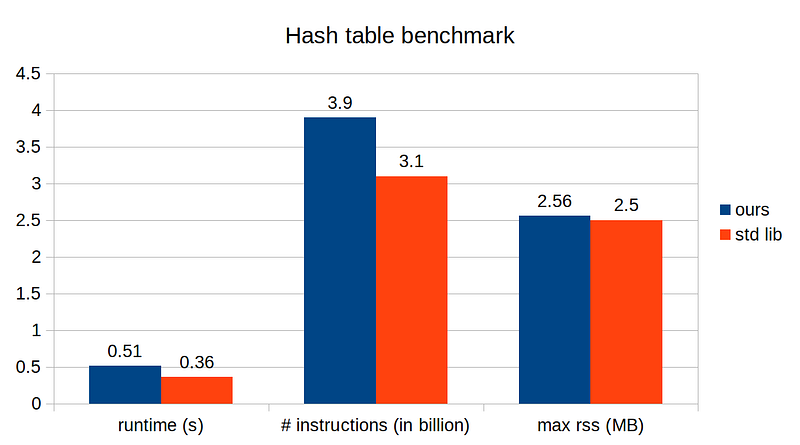
In the next story, we will optimize our implementation even further, so stay tuned!