Rust implementation challenge — hash table part 4
Continuing from our journey to write our own hash table from scratch, we will improve and optimize our implementation from an algorithmic perspective.
One possible update to the implementation is to be able to recycle a tombstone entry. Currently, tombstones are essentially dead entries that just waste the array space. The only way to clear them out is when we call resize() method that instantiates a new hash table. A more efficient usage of tombstones is to recycle them if possible.
This improvement is straightforward. We need to modify insert() method so that if a tombstone has been encountered during the probe, we save it in case we can recycle it. If we failed to find an entry that matches the given key, then we insert the key, value pair into this saved tombstone entry, rather than a new vacant entry. I will leave the actual implementation as an exercise. With this change, I was able to see about 4% improvement in the runtime with the synthetic benchmark.
There is a much better patch we can apply, which can bring us not only greater performance gain but also much lessons and insight — robin hood hashing. This algorithm is quite clever and reminded me why algorithms are essential in software engineering.
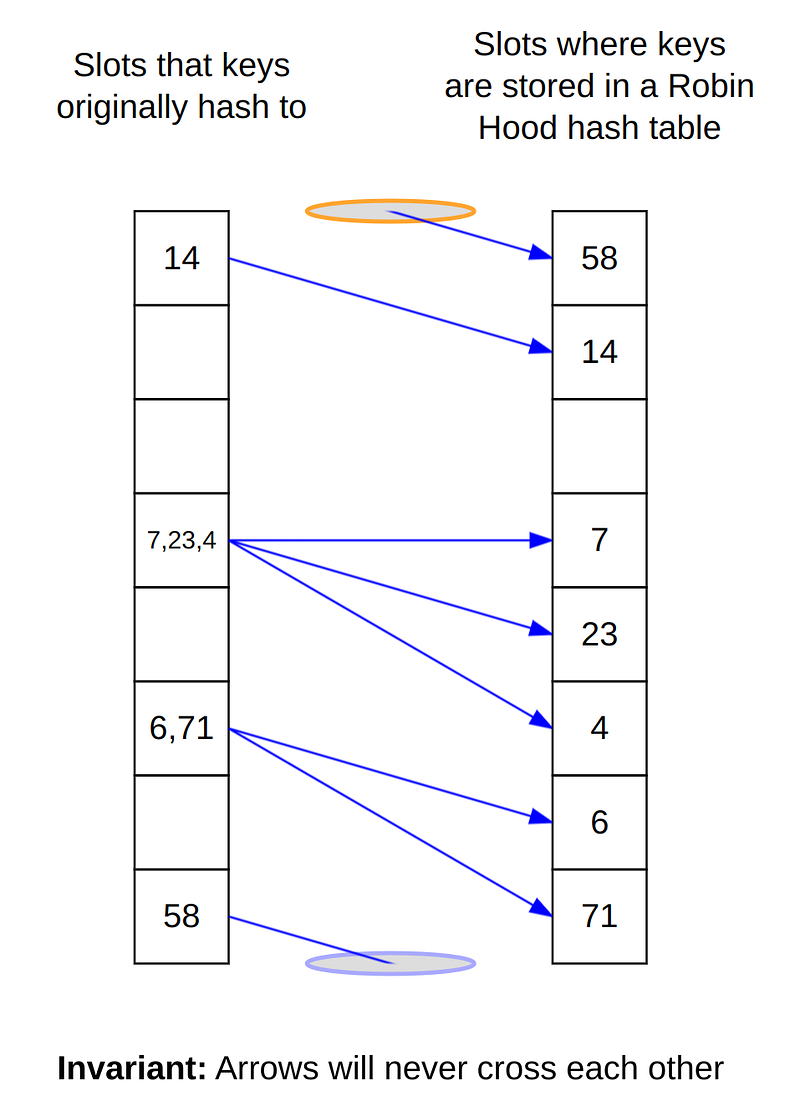
Robin hood hashing is a technique for collision resolution in an open-addressing hash tables. One key concept is probe sequence length, or PSL. This is the distance between the original location (home slot) pointed by the hash value to the actual location of the item. When there is no hash collision, every item will have 0 PSL. As more and more items collide, these items will be placed further away from the ideal location.
The basic idea of robin hood hashing technique is to reduce variance in PSL, because item lookup time is proportional to PSL. This is achieved by sorting the items according to their home slot location.
https://programming.guide/robin-hood-hashing.html
With this property, we can early-stop our probing when we encounter an item that belongs to a different home slot. In the diagram above, if our home slot coincides with 7,23,4, we early-terminate the probing at the entry that contains 6, because it belongs to a different home slot. How do we tell where is the home slot for each item? Well, we can simply save the PSL value along with the key and value per each entry. The trade off is that we will increase the memory consumption.
The main update would go into insert_helper() method. To ensure items are sorted by their home slots, we essentially carry out a bubble sort — we swap adjacent items if necessary as we probe. I never thought bubble sort would be of any practical use, but here it is a glorious come-back of bubble-sort algorithm!
Another advantage of robin hood hashing is that we can eliminate tombstones. That is, our entries are either vacant or occupied. For that, we need to modify remove() method — when an entry with the matching key is found, mark it as vacant. We continue to probe and shift down following keys one slot back in position to fill in the gap. However, we can early-stop when we encounter an item that has 0 PSL, meaning that the item is already in its ideal location.
The patch is a lot, so instead of listing all the diff here, I will just share the complete code here I recommend that you try implementing it yourself to really understand the technique. And here is benchmark result with our shiny robin hood hashing technique
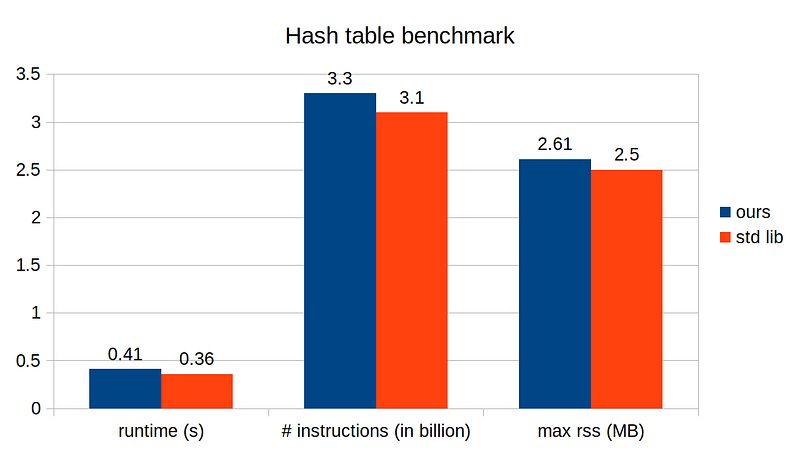
The runtime reduced from 0.51s to 0.41s compared to our previous implementation, whopping 20% decrease, making our implementation a step closer to the standard library’s. Not bad for just around 200 lines of code. With this promising result, our next challenge is to beat the standard implementation on this particular benchmark. Stay tuned for the next story!