Rust implementation challenge — hash table part 6
We have come a long journey implementing our own hash table in Rust. We started off by writing the hash table implementation from scratch, supporting a subset of the standard library’s API. We completed a fully functional implementation, wrote a test and ran a benchmark. Our first version ran at 6.37s compared to the standard’s 0.36s, but we progressively improved it over several iterations and finally reached on-par performance with the standard’s.
Today, we will further improve the performance, not by improving the algorithm or implementation, but rather by tuning a parameter. Though it is often overlooked as a simple hack, tuning a set of parameters to optimize performance for an expected use case is a legit and effective way.
In our hash table implementation, there are several parameters we may tune
- the starting number of array, which is set as 64
- the load factor threshold at which the the array size increases; currently set to 0.75
- and the rate of array resize, which is set as 2x
The first one only affects for the case with a small number of entries, and the last one is pretty much tied, since we need to make sure array sizes are powers of 2. We are only left with the load factor threshold, which will have significant impact on the performance of the hash table in general. Let’s run the benchmark for different values of load factor:
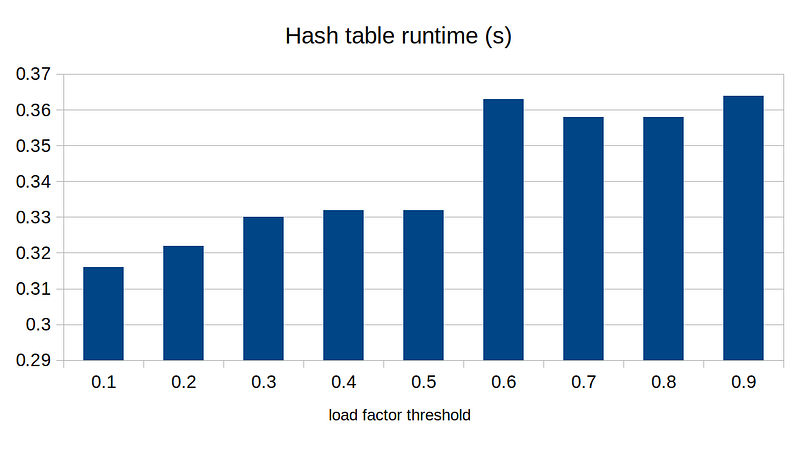
In general, the lower the load factor threshold, the faster it runs. This is probably because lower load factor reduces the chance of hash collisions. Does this mean we shall choose the load factor of 0.1 to maximize its runtime performance?
All engineering decisions are about trade-offs.
If we lower the load factor threshold, we would expect to see reduced runtime, as show in the plot above, but we will certainly increase the memory footprint, since our array will be more sparse.
If we want to minimize runtime regardless of the memory cost, then load factor threshold of 0.1 might be the optimal choice. If we want to balance the runtime and memory consumption, then maybe load factor threshold of 0.5 works better.
Note that we are vastly simplifying our analysis here — in practice, we would run a bunch of benchmark tests on different use cases and scenarios.
Finally, let’s set our load factor threshold to, say 0.5, and run benchmark on memory consumption and instructions.
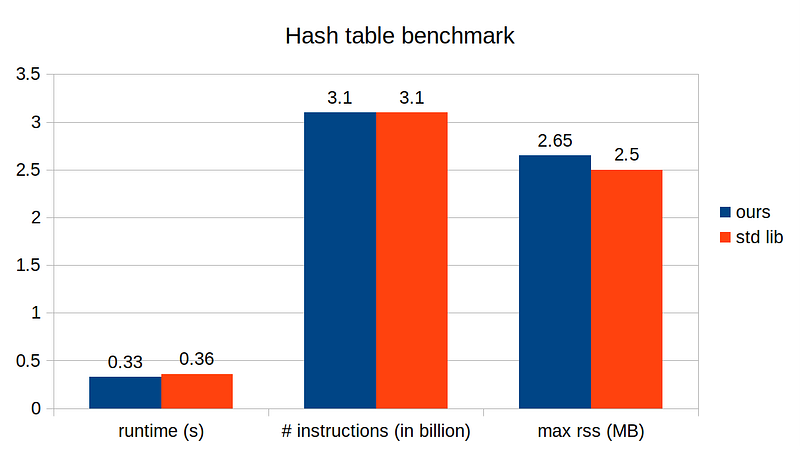
With our fine-tuned hash table, we run about 10% faster compared to the standard library’s, though it has a bit higher memory footprint. Does this mean our implementation is better than the standard’s? Probably not. The standard implementation has probably gone through a much more rigorous performance analysis and unit tests. Our implementation runs faster probably because we fine-tuned it for this particular test case running on a single system/platform. Nevertheless, our implementation isn’t so bad for just a few hundred lines of code!