Rust — write gunzip from scratch 6
In this series, we will be writing gunzip decompressor from scratch in Rust. We want to write it ourselves not only to learn Rust but also to understand how it .gz compression works under the hood. For full source code, check out this Github repo. You can find all articles of the series below
- part 1:
main()function and skeletal structure - part 2:
bitreadmodule for reading bits from a byte stream - part 3:
gzipheader & footer for parsing the metadata and checksum - part 4:
inflatefor block type 0 (uncompressed) data - part 5:
codebookandhuffman_decodermodules for decoding Huffman codes - part 6:
lz77andsliding_windowmodules for decompressing LZ77-encoded data - part 7:
inflatefor block type 1 and 2 (compressed) data using fixed or dynamic Huffman codes - part 8:
checksum_writemodule for verifying the decompressed data - part 9: performance optimization
- part 10: multithread support
- part 11: streaming support
- part 12: memory optimization
- part 13: bug fix to reject non-compliant
.gzfile
Today, let’s dive deeper into the main algorithm of Deflate, which is LZ77. The LZ77 algorithm compresses data by replacing repeated sequences of bytes with reference to previous occurrences. It uses a sliding window of a fixed size to look for matches between the current data and the past data. Today, we will implement the LZ77 decoding algorithm shown below

Let first define LZ77 Code as an enum:
// src/lz77.rs
pub const END_OF_BLOCK: u32 = 256;
pub const MAX_DISTANCE: u16 = 1 << 15; // 32kB
pub const MAX_LENGTH: u16 = 258;
#[derive(PartialEq, Eq, Debug)]
pub enum Code {
Literal(u8), // < 256
EndOfBlock, // == 256
Dictionary { distance: u16, length: u16 }, // 257..285
}
We will write a function decode() that does exactly what the above algorithm explains. To minimize dependencies between modules, we will assume that
- the caller provides an
iteratorover LZ77codes(will implement later) - the caller takes care of the sliding
window, which consists of the past written data and the buffer to write new data. - the caller will write to the standard output
Shown below is the LZ77 decode function signature and its return value
// append to src/lz77.rs
use crate::error::{Result, Error};
pub enum DecodeResult {
Done(usize), // all symbols are exhausted and written
WindowIsFull(usize), // cannot proceed further because the window is full
Error(Error),
}
pub fn decode(
window: &mut [u8],
boundary: usize,
codes: &mut impl Iterator<Item = Result<Lz77Code>>,
) -> Result<DecodeResult> {
todo!()
}
The input parameter window is the sliding window where decompressed data is to be written, where boundary is the position of the next byte to be written. Below depicts time evolution of window and its boundary value:
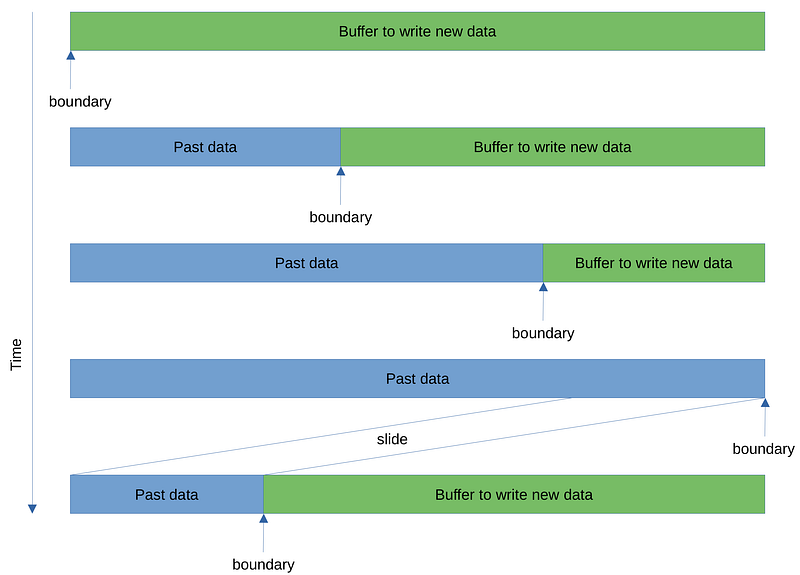
The sliding window starts with an empty history (past data). As we write data into the window, the boundary between the past data (written data) and new data moves to the right. When we no longer have enough space to write more data, decode function returns WindowIsFull variant with the size of new data written during the call. Then, the caller will need to slide the window so that at most 32kB of past data is kept — Deflate supports up to 32kB distance, as defined in MAX_DISTANCE above. The caller will call decode() function and the process repeats until all codes are exhausted.
With this interface, the implementation of decode function should be straightforward
// replace in src/lz77.rs
pub fn decode(
window: &mut [u8],
boundary: usize,
codes: &mut impl Iterator<Item = Result<Code>>,
) -> Result<DecodeResult> {
let mut idx = boundary; // position to write to
if idx + MAX_LENGTH as usize >= window.len() {
return Ok(DecodeResult::WindowIsFull(idx - boundary));
}
for code in codes {
match code? {
Code::Literal(x) => {
window[idx] = x;
idx += 1;
}
Code::Dictionary { distance, length } => {
let mut distance = distance as usize;
let mut length = length as usize;
if distance > idx {
return Err(Error::DistanceTooMuch);
}
let begin = idx - distance;
while length > 0 {
let n = distance.min(length);
window.copy_within(begin..begin + n, idx);
idx += n;
length -= n;
distance += n;
}
}
Code::EndOfBlock => {
return Ok(DecodeResult::Done(idx - boundary));
}
}
if idx + MAX_LENGTH as usize >= window.len() {
return Ok(DecodeResult::WindowIsFull(idx - boundary));
}
}
Err(Error::EndOfBlockNotFound)
}
// append in src/lib.rs
pub mod lz77;
// replace in src/error.rs
pub enum Error {
StdIoError(ErrorKind),
EmptyInput,
InvalidGzHeader,
InvalidBlockType,
BlockType0LenMismatch,
InvalidCodeLengths,
HuffmanDecoderCodeNotFound,
DistanceTooMuch,
EndOfBlockNotFound,
}
A few things to note
- We return
WindowIsFullif we have fewer thanMAX_LENGTHbytes left to ensure we have enough space for the worst case. - We return an error if the distance is further than past data.
- We return an error if
EndOfBlocksymbol is not found - Length can be larger than distance. This is a valid
Deflateformat. Note this excerpt from RFC1951 below

While at it, let’s also implement SlidingWindow struct
// append to src/lib.rs
pub mod sliding_window;
// src/sliding_window.rs
use crate::lz77::MAX_DISTANCE;
pub const WINDOW_SIZE: usize = MAX_DISTANCE as usize * 3;
pub struct SlidingWindow {
data: Vec<u8>,
cur: usize, // where next data is to be written
}
impl SlidingWindow {
pub fn new() -> Self {
Self {
data: vec![0; WINDOW_SIZE],
cur: 0,
}
}
/// entire window
pub fn buffer(&mut self) -> &mut [u8] {
&mut self.data
}
/// Write buffer size is guaranteed to be at least 64kB after `slide()`
pub fn write_buffer(&mut self) -> &mut [u8] {
&mut self.data[self.cur..]
}
/// Slide the data so that at most 32kB of the most recent history is kept
pub fn slide(&mut self, n: usize) {
let end = self.cur + n;
if end > MAX_DISTANCE as usize {
let delta = end - MAX_DISTANCE as usize;
self.data.copy_within(delta..end, 0);
self.cur = MAX_DISTANCE as usize;
} else {
self.cur = end;
}
}
/// index to write buffer
pub fn boundary(&self) -> usize {
self.cur
}
}
Here, we are setting the window size as 96kB because we want to ensure that the write buffer is at least 64kB in size (96kB - 32kB), which is the maximum size we can read from an uncompressed block, i.e., block type 0. In Deflate, the history can span over different blocks, including uncompressed blocks. With that, let’s modify inflate_block0() method in inflate module to write history into the sliding window.
// append to src/inflate.rs
use crate::sliding_window::SlidingWindow;
// replace src/inflate.rs
pub struct Inflate<R: BitRead, W: Write> {
reader: R,
writer: W,
window: SlidingWindow,
}
// replace src/inflate.rs
pub fn new(reader: R, writer: W) -> Self {
Self { reader, writer, window: SlidingWindow::new() }
}
// replace in src/inflate.rs
fn inflate_block0(&mut self) -> Result<()> {
self.reader.byte_align();
let len = self.reader.read_bits(16)?;
let nlen = self.reader.read_bits(16)?;
if len ^ nlen != 0xFFFF {
Err(Error::BlockType0LenMismatch)
} else {
let buf = &mut self.window.write_buffer()[..len as usize];
self.reader.read_exact(buf)?;
self.writer.write_all(&buf)?;
self.window.slide(len as usize);
Ok(())
}
}
Now, raw data read from the uncompressed block can also participate in LZ77 decoding algorithm as required by the specification.
As always, we verify that the code compiles. In the next article, we will complete implementation of decompression for block type 1 and 2, so stay tuned!
Previous in series: https://techhara.me/posts/2023-10-02_rust—write-gunzip-from-scratch-5-670beb29b11f/
Next in series: https://techhara.me/posts/2023-10-10_rust—write-gunzip-from-scratch-7-15747e6032e4/