Compression — range coding
Today, let’s have a look at a popular lossless data compression algorithm called range coding. This is one of the methods in the family of entropy coding. As with entropy coding family, the main idea is to represent more frequent symbols with shorter code lengths. The difference with Huffman coding is that the former is a symbol-coding scheme where each symbol gets a fixed value (code) per symbol whereas the latter is a stream-coding scheme where each symbol is assigned a range of values. This allows stream-coding to achieve higher compression ratio than symbol-coding.
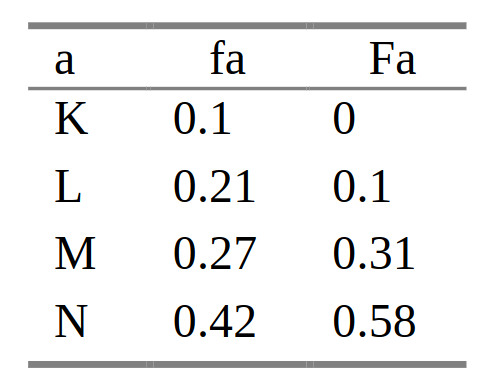
The range coding works by assigning each symbol a range of values proportional to its probability. At a given time, both an encoder and a decoder holds its current range, which consists of the starting point (let’s call it low) and its ending point (call it high). The range is divided up proportional to probabilities of next symbol.
The encoder emits the highest byte if both low and high share the same highest byte, drops the highest byte and shifts left by a byte. The decoder does the opposite — it reads a value, deduces the range that contains the value. If both low and high share the same highest byte of the value, then it discards it, reads the next value. In essence, the ranges should sync exactly between the encoder and decoder.
Below is range progression in decimal settings from the original paper.
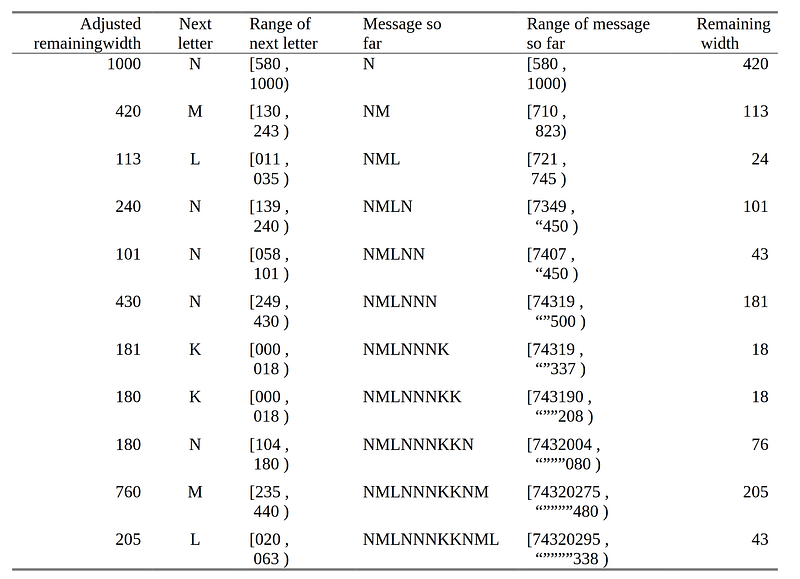
To fully understand the algorithm, I decided to implement a simple compression/decompression utility using range coding. Though the concept is straightforward, the actual implementation was quite tricky. Furthermore, I wasn’t able to find resources on simple / basic implementation of this on the internet, which made it more challenging.
Based on Wikipedia as a reference, I wrote simple compression purely on range-coding. The program consists of an encoder and decoder. The encoder takes an arbitrary data from stdin, encodes using range-coding, and outputs to stdout. Conversely, the decoder takes in range-coded data from stdin, decodes and outputs the raw data to stdout.
Specifically, each file is broken into blocks of up to 32kB. A frequency table is generated per block and prepended so that the decoder can read the table. Using the same frequency table, the decoder reproduces the input data.
For Linux source code tarball of size 1.4GB, the compressed file, including the frequency tables, was around 842MB, so the compression ratio is around 1.66, much lower than typical compression algorithm, such as gzip, bzip2, or xz. As a reference, gzip compressed the same file to about 223MB.
If you are interested in simple yet functional implementation (though probably not efficient) to learn and understand, you can check out my repo here. If you are looking for more robust and more efficient implementation, check out range-encoding and constriction crates. If you are looking for its sibling arithmetic coding implementation, check out this project and its source code from this legendary software engineer.