Learn from Haskell — generalized fold
Today, let’s apply a lesson we learn from Haskell to non-Haskell languages, such as Rust. Learning Haskell makes you a better programmer for non-Haskell languages!
Binary Tree
A binary Tree is a hierarchical data structure in which each node has at most two children, commonly referred to as the left and right child. It is a recursive data structure in that each child is a binary tree.
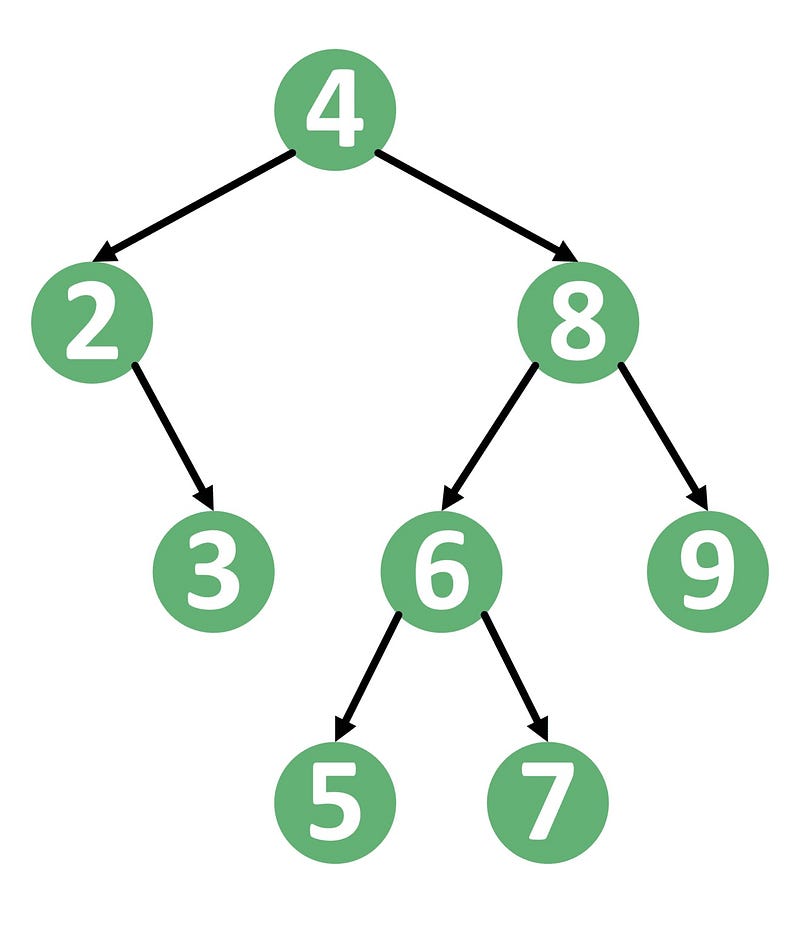
We are going to use an enum to define a simple binary tree that contains i32 type item
enum BinaryTree {
Empty,
Node {
left: Box<BinaryTree>,
x: i32,
right: Box<BinaryTree>,
},
}
Suppose you are tasked to implement the following functions:
// number of nodes
fn len(root: &BinaryTree) -> usize {
todo!()
}
// depth of the tree
fn depth(root: &BinaryTree) -> usize {
todo!()
}
// minimum element
fn min(root: &BinaryTree) -> Option<i32> {
todo!()
}
// maximum element
fn max(root: &BinaryTree) -> Option<i32> {
todo!()
}
// traverse in-order (LNR)
fn iter_in_order(root: &BinaryTree) -> impl Iterator<Item = i32> {
todo!()
}
// traverse pre-order (NLR)
fn iter_pre_order(root: &BinaryTree) -> impl Iterator<Item = i32> {
todo!()
}
// traverse post-order (LRN)
fn iter_post_order(root: &BinaryTree) -> impl Iterator<Item = i32> {
todo!()
}
Exercise
Pause here and try to implement them yourselves here — you will get the most out of this post if you actually spend some time implementing them. Refer to this wiki page for a refresher on tree traversal.
If you really did the exercise, you may have noticed that all these functions are most likely implemented in a very similar recursive pattern — you start off from the root, do a pattern match, return a simple answer for Empty case. As for Node, you have probably called the function recursively to the children and combine the result and return some answer.
A good programmer should avoid repeating oneself in the code. That is, we should factor out the common logic from all these function implementations and simplify our code as much as possible. That is where fold from functional programming languages like Haskell comes into play.
Fold
Rust already has fold method for Iterators, but that is only a special case of fold that applies to a list or an iterator. We can generalize this pattern for our BinaryTree struct as well. What it will do is exactly what I have explained above.
// apply f recursively to non-empty node. return init for an empty node
fn fold<B: Clone>(root: &BinaryTree, init: B, f: fn(B, i32, B) -> B) -> B {
match root {
BinaryTree::Empty => init,
BinaryTree::Node { left, x, right } => {
let l = fold(&left, init.clone(), f);
let r = fold(&right, init, f);
f(l, *x, r)
},
}
}
Here, B is the return-type, and f is a function that we want to apply recursively. Now that we have this helper function, let’s go ahead and implement the len() and depth() functions using fold:
fn len(root: &BinaryTree) -> usize {
fold(root, 0, |l, _, r| 1 + l + r)
}
fn depth(root: &BinaryTree) -> usize {
fold(root, 0, |l, _, r| 1 + l.max(r))
}
All we need to do is the provide the correct init and f. In the case of len(), we are counting the number of elements, so init is 0 for Empty. As for f, we just add the element itself (+1) to the number of elements from left subtree and right subtree.
Similarly for the case of depth(), the depth of Empty is 0, so that’s the init. As for f, we add the depth itself (+1) to the maximum depth from the left subtree and right subtree.
Now, let’s proceed with min() and max() functions.
fn min(root: &BinaryTree) -> Option<i32> {
fold(&root, None,|l, x, r| {
Some(l.unwrap_or(x).min(r.unwrap_or(x)))
})
}
fn max(root: &BinaryTree) -> Option<i32> {
fold(&root, None,|l, x, r| {
Some(l.unwrap_or(x).max(r.unwrap_or(x)))
})
}
Again, one-line implementations. In the case of Empty we should return None, so that’s what init is. For Node we return min/max of x with the recursive results from left and right subtrees.
Finally, let’s do the three variants of iter() functions. The idea is to apply fold to collect a vector of the elements in the desired order first, from which we return an iterator.
fn iter_in_order(root: &BinaryTree) -> impl Iterator<Item = i32> {
fold(&root, Vec::new(), |mut l, x, r| {
l.push(x);
l.extend(r);
l
}).into_iter()
}
fn iter_pre_order(root: &BinaryTree) -> impl Iterator<Item = i32> {
fold(&root, Vec::new(), |l, x, r| {
let mut xs = vec![x];
xs.extend(l);
xs.extend(r);
xs
}).into_iter()
}
fn iter_post_order(root: &BinaryTree) -> impl Iterator<Item = i32> {
fold(&root, Vec::new(), |mut l, x, r| {
l.extend(r);
l.push(x);
l
}).into_iter()
}
Again, just a few lines of code. We just need to vary the order in which we create the vector within f.
So how did you do? Before learning Haskell, I implemented every function naively, repeating the same match root { ... } pattern. Now, I can see that this is a generalized fold pattern and would create fold() function first and implement the rest using this function. Personally, I believe this significantly improves the readability and quality of the code.