Python — boost performance with asyncio
Today, let’s have a look at a simple example to boost efficiency of a simple Python program by using asyncio.
Here is what we want to do. Our program takes in a list of files and will compute a hash of each file. It will then return a dictionary with the filename as the key and the hash as the value. Pretty simple, right?
Synchronous implementation
Let’s start with the most straightforward implementation.
# sync.py
import argparse
import hashlib
def hash(data):
return hashlib.sha256(data).hexdigest()
def get_hashes(file_list, hash_function):
def read_and_hash(file_name):
with open(file_name, 'rb') as file:
file_data = file.read()
file_hash = hash_function(file_data)
return file_name, file_hash
return dict(map(read_and_hash, file_list))
parser = argparse.ArgumentParser()
parser.add_argument('files', nargs='+')
args = parser.parse_args()
files = args.files
print(get_hashes(files, hash))
We iterate over the files, read the data, compute the hash, and then create a dictionary. Note that this is a synchronous implementation, meaning we are blocked by the file read operation. We process each file one by one in a sequential manner. When I test it with a few large-size files, I get 2.4s runtime.
Asynchronous implementation
Now it is time to make use of Python’s asyncio module and run this in a non-blocking way. Below shows modification we need to run with asyncio.
--- sync.py
+++ async.py
@@ -1,20 +1,23 @@
import argparse
+import asyncio
+import aiofiles
import hashlib
def hash(data):
return hashlib.sha256(data).hexdigest()
-def get_hashes(file_list, hash_function):
- def read_and_hash(file_name):
- with open(file_name, 'rb') as file:
- file_data = file.read()
+async def get_hashes(file_list, hash_function):
+ async def read_and_hash(file_name):
+ async with aiofiles.open(file_name, 'rb') as file:
+ file_data = await file.read()
file_hash = hash_function(file_data)
return file_name, file_hash
- return dict(map(read_and_hash, file_list))
+ return dict(await asyncio.gather(*map(read_and_hash, file_list)))
parser = argparse.ArgumentParser()
parser.add_argument('files', nargs='+')
args = parser.parse_args()
files = args.files
-print(get_hashes(files, hash))
+print(asyncio.run(get_hashes(files, hash)))
First, we import asyncio and aiofiles modules. We use aiofiles.read() in place of read(). With this, we declare the functions to be async, i.e., a coroutine. Also, we invoke async.gather() method to run the coroutines concurrently, as opposed to map() that runs sequentially. Finally, we execute get_hashes() coroutine with asyncio.run() method.
With these changes, I test on the same files as before and obtain 1.5s runtime.
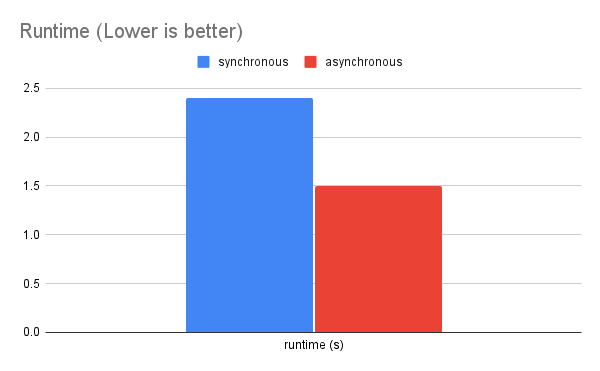
So, how is this running much faster? That’s because file IO is the major bottleneck. The synchronous version of the program spends significant amount of time idling, waiting for the data to be available. We are wasting valuable CPU cycles.
On the other hand, the asynchronous implementation minimizes idling time by computing other tasks that can be performed without waiting, such as computing the hash for the file whose data is already available. The program still runs with a single process but is able to switch back and forth between different coroutines because they are run concurrently but not in parallel. One thing to note is that if only a single file is provided, then there would be virtually no difference between the two implementations.
Alright, hopefully this has been an insightful example. You can find the full asynchronous implementation below
import argparse
import asyncio
import aiofiles
import hashlib
def hash(data):
return hashlib.sha256(data).hexdigest()
async def get_hashes(file_list, hash_function):
async def read_and_hash(file_name):
async with aiofiles.open(file_name, 'rb') as file:
file_data = await file.read()
file_hash = hash_function(file_data)
return file_name, file_hash
return dict(await asyncio.gather(*map(read_and_hash, file_list)))
parser = argparse.ArgumentParser()
parser.add_argument('files', nargs='+')
args = parser.parse_args()
files = args.files
print(asyncio.run(get_hashes(files, hash)))
Resources
If you want to learn more about it, below are some useful resources to read