Rust — performance overhead of RefCell
how much of runtime cost does it incur? Is it enough to avoid it completely?
Rust — performance overhead of RefCell
Overhead:
RefCellintroduces runtime checks for borrowing, which can lead to a slight performance hit.- These checks ensure runtime safety by preventing multiple mutable references at the same time.
Context Matters:
- In most scenarios, the overhead from
RefCellis negligible compared to other bottlenecks within an application. - Performance hit from due to increase in data structure size may be more significant than runtime check itself.
- Try to avoid explicit construction of
Ref<T>andRefMut<T>to minimize overhead.
Profile and Measure:
- Profile your code to identify existing bottlenecks first.
- Measure the impact of
RefCell.
Let’s briefly go over what RefCell does. In most of the use cases, RefCell is used in conjunction with Rc to wrap an object that is mutually owned by multiple owners and may be modified by any of them. This is essentially a runtime-version of Rust’s borrow checker. Contrary to compile-time borrow-checker, which costs nothing at runtime, RefCell’s dynamic borrow checker does incur a small cost during runtime. The question is,
how much of runtime cost does it incur? Is it enough to avoid it completely?
Under the hood
Before we run experiments, let’s go over how RefCell actually works internally. RefCell keeps the data along with a isize counter. This results in 8 additional bytes to store it on a typical 64-bit architecture. In fact, this could be as much as 15-bytes of additional storage cost if the underlying data is just a byte. For example, RefCell<u8> is 16-bytes in size, compared to just 1-byte of u8— this is due to memory alignment. In addition, when we explicitly pass around Ref<T> or RefMut<T> objects, there is the same 8 bytes of additional cost for the object, too, compared to raw reference &T or &mut T. We’ll discuss what this means in the next section.
With this in mind, here is our first consideration
RefCellincurs 8–15 additional bytes of memory cost- Explicit
Ref<T>orRefMut<T>object construction also incurs 8 additional bytes of memory cost
In terms of runtime, operations incurred by RefCell consist of an increment/decrement of the counter as well as branching to see if there is already a borrow before doing borrow_mut(). In addition, there will be cost to explicitly construct Ref<T> or RefMut<T> fat pointers.
CPU Instructions
Let’s verify with compiler explorer. First, immutable borrow with and without RefCell:
pub fn refcell_borrow(x: &RefCell<i64>) -> Ref<i64> {
x.borrow()
}
/*
refcell_borrow:
mov rax, qword ptr [rdi]
movabs rcx, 9223372036854775806
cmp rax, rcx
ja .LBB2_2
inc rax
mov qword ptr [rdi], rax
lea rax, [rdi + 8]
mov rdx, rdi
ret
.LBB2_2:
push rax
lea rdi, [rip + .L__unnamed_3]
call qword ptr [rip + core::cell::panic_already_mutably_borrowed::hce6e9a46af62db8c@GOTPCREL]
*/
pub fn raw_borrow(x: &i64) -> &i64 {
x
}
/*
raw_borrow:
mov rax, rdi
ret
*/
There is a lot more instructions for RefCell. It compares the counter to verify it is OK to create another Ref object, increment the counter, and construct the Ref wrapped-object, as we have described above. There is actually additional not-so-obvious instructions to be incurred: destruction of Ref<T> object and decrementing the counter.
pub fn refcell_borrow_destruct(x: Ref<i64>) -> i64 {
*x
}
/*
refcell_borrow_destruct:
mov rax, qword ptr [rdi]
dec qword ptr [rsi]
ret
*/
Now, what about mutable borrow?
pub fn refcell_borrow_mut(x: &RefCell<i64>) -> RefMut<i64> {
x.borrow_mut()
}
/*
refcell_borrow_mut:
cmp qword ptr [rdi], 0
jne .LBB3_2
mov qword ptr [rdi], -1
lea rax, [rdi + 8]
mov rdx, rdi
ret
.LBB3_2:
push rax
lea rdi, [rip + .L__unnamed_4]
call qword ptr [rip + core::cell::panic_already_borrowed::h25cd4ace6912ad46@GOTPCREL]
*/
pub fn refcell_borrow_mut_destruct(x: RefMut<i64>) -> i64 {
*x
}
/*
refcell_borrow_mut_destruct:
mov rax, qword ptr [rdi]
inc qword ptr [rsi]
ret
*/
pub fn raw_borrow_mut(x: &mut i64) -> &mut i64 {
x
}
/*
raw_borrow_mut:
mov rax, rdi
ret
*/
Interestingly, fewer instructions than borrow(), but still a few more than &mut T. In addition, there is also some overhead from destruction of RefMut<T> object too.
Now, so far we have examined the case when we explicitly create Ref<T> and RefMut<T> objects, or the fat pointers. However, we could reduce the overhead significantly if we can run operations inline. That is, don’t pass around Ref<T> or RefMut<T> but rather perform operations directly on RefCell::borrow() and RefCell::borrow_mut().
fn refcell_inline(x: &RefCell<i64>) -> i64 {
*x.borrow_mut() += 1;
*x.borrow()
}
/*
refcell_inline:
cmp qword ptr [rdi], 0
jne .LBB7_2
mov rax, qword ptr [rdi + 8]
inc rax
mov qword ptr [rdi + 8], rax
mov qword ptr [rdi], 0
ret
.LBB7_2:
push rax
lea rdi, [rip + .L__unnamed_4]
call qword ptr [rip + core::cell::panic_already_borrowed::h25cd4ace6912ad46@GOTPCREL]
*/
fn raw_inline(x: &mut i64) -> i64 {
*x += 1;
*x
}
/*
raw_inline:
mov rax, qword ptr [rdi]
inc rax
mov qword ptr [rdi], rax
ret
*/
As you can see, there isn’t really much overhead other than branching, which we can safely ignore assuming successful speculative execution. By inlining, we avoid the counter increment/decrement and fat pointer construction/destruction overhead.
Prefer inline execution and try to avoid explicitly constructing
Ref<T>orRefMut<T>for minimal overhead
Benchmark 1
Let’s start with a very simple benchmark. Let’s compare how long it takes to (1) clone (immutable) and (2) increment (mutable) an array of (a) T and (b) RefCell<T>. This is probably not a typical scenario one would use RefCell, but nevertheless this will shed some light on the performance hit from RefCell.
// immutable
fn clone_refcell<T: Clone>(src: &[RefCell<T>], dst: &mut [T]) {
for (s, d) in src.iter().zip(dst) {
*d = s.borrow().clone();
}
}
// mutable
fn increment_refcell<T, U>(xs: &[RefCell<T>], delta: U)
where
T: AddAssign<U>,
U: Copy,
{
for x in xs.iter() {
*x.borrow_mut() += delta;
}
}
// immutable
fn clone_raw<T: Clone>(src: &[T], dst: &mut [T]) {
for (s, d) in src.iter().zip(dst) {
*d = s.clone();
}
}
// mutable
fn increment_raw<T, U>(xs: &mut [T], delta: U)
where
T: AddAssign<U>,
U: Copy,
{
for x in xs.iter_mut() {
*x += delta;
}
}
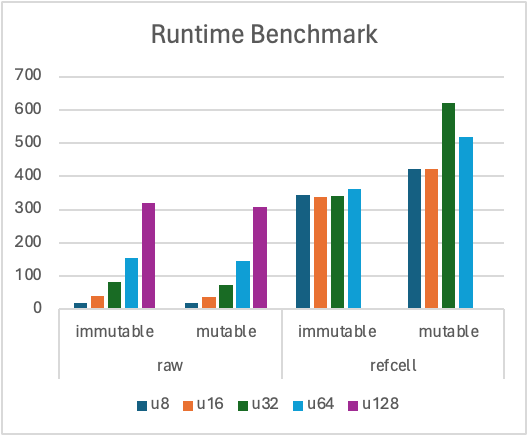
With the raw type T, the runtime grows exponentially as we double the data structure size, i.e., u8 -> u16 -> u32 -> u64 -> u128. On the other hand, RefCell<T> runtime exhibits very different behavior . In particular, it is flat for immutable operation. This pattern clearly indicates that the runtime is bottle-necked by the data access, i.e., how many elements can fit in a cache line and how much of it can be stored in cache. Note that the memory size of u128 and RefCell<u64> are both 16-bytes. By comparing these two, we can effectively isolate the impact only from the CPU instructions. In this case, RefCell<T>::borrow() operations pretty much has no overhead compared to &T while RefCell<T>::borrow_mut() does seem to incur some noticeable overhead compared to &mut T.
Benchmark 2
So, does this mean we should avoid RefCell because its mutable borrow is much slower? Probably not. In practice, T is likely a larger data structure and the existing runtime overhead is likely much larger compared to the RefCell overhead . Here is another, perhaps more realistic benchmark with T = HashMap<String, i32>.
// immutable
fn clone_raw<T>(hashmap: &HashMap<String, T>, xs: &[T], dst: &mut [T])
where
T: Clone + ToString,
{
for (s, d) in xs.iter().zip(dst.iter_mut()) {
hashmap.get(&s.to_string()).map(|x| *d = x.clone());
}
}
// immutable
fn clone_refcell2<T>(hashmap: &RefCell<HashMap<String, T>>, xs: &[T], dst: &mut [T])
where
T: Clone + ToString,
{
for (s, d) in xs.iter().zip(dst.iter_mut()) {
hashmap.borrow().get(&s.to_string()).map(|x| *d = x.clone());
}
}
// mutable
fn increment_raw<T, U>(hashmap: &mut HashMap<String, T>, xs: &[T], delta: U)
where
T: Clone + ToString + AddAssign<U>,
U: Copy,
{
for s in xs.iter() {
hashmap.get_mut(&s.to_string()).map(|n| *n += delta);
}
}
// mutable
fn increment_refcell<T, U>(hashmap: &RefCell<HashMap<String, T>>, xs: &[T], delta: U)
where
T: Clone + ToString + AddAssign<U>,
U: Copy,
{
for s in xs.iter() {
hashmap
.borrow_mut()
.get_mut(&s.to_string())
.map(|n| *n += delta);
}
}
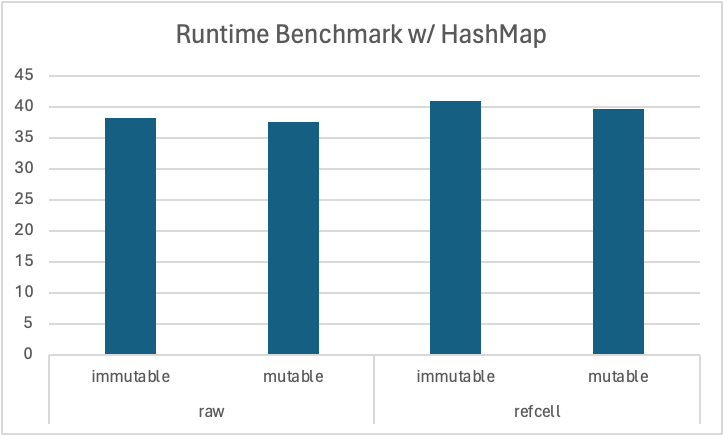
This time, the performance overhead by wrapping with RefCell is not that significant because the overhead from other operations is much larger than the overhead from RefCell itself.
Recall 80/20 rule in software— 20% of the code is causing 80% of the bottleneck. Identify your application’s bottleneck first.
RefCelloverhead may not matter.
Conclusion
The RefCell overhead by itself is not that significant. However, it adds 7–15 bytes memory footprint, which may cause significant delay in data access if we are dealing with an array of them. Profile your application first to see where and how much is the existing bottleneck to make a better judgment as to whether RefCell overhead would be a significant add-on. Finally, try to avoid creating Ref<T> and RefMut<T> objects to minimize overhead.