Concurrency — function, subroutine, coroutine
Today, let’s go over the difference among a function, subroutine, and a coroutine. We will also build a simple app to demonstrate the effective of coroutine.
Concepts
In general, you can assume a function and subroutine are equivalent. A function or subroutine is a block of code that is executed as a whole. In other words, when you call a function, you expect that the instructions within the function to run till the end with the highest priority without any pause or digression. On the other hand, a coroutine is a block of code that can be executed with digression.
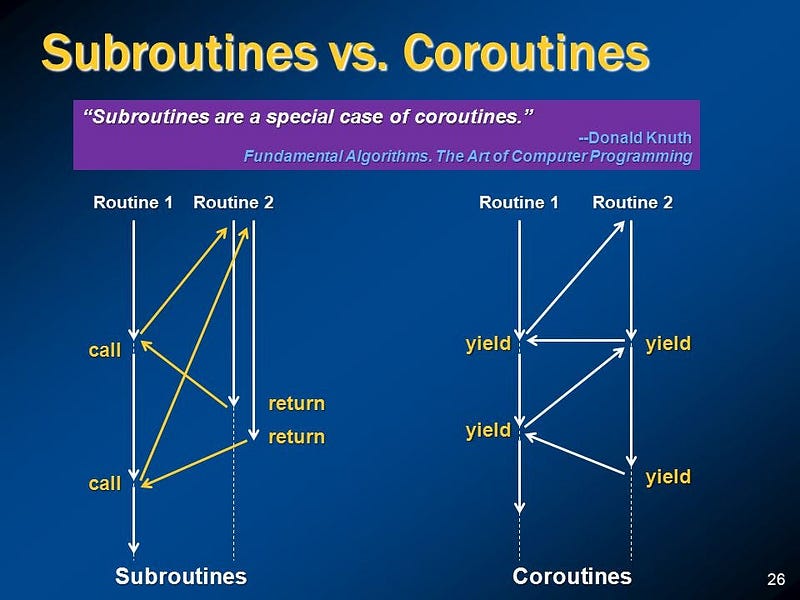
The diagram above depicts how the two differ in terms of control flow. On the left, a subroutine must complete its execution until it yields the control back to the caller. On the other hand, a coroutine can yield its control and wait for a concurrent coroutine to do the work first. The coroutine will pick up the left-over work when it receives back the control.
Another name for subroutine is a blocking or synchronous function. On the other hand, a coroutine is also referred to as an asynchronous or non-blocking function. In this context, function encompasses both subroutine and coroutines.
Use cases
A function or subroutine is used to minimize code duplication. Coroutine serves the same purpose but with an additional purpose: efficient utilization of the resource.
Not every tasks are CPU-intensive. Some tasks are just inherently slow due to the nature of it. For example, communication through network requires very long wait-time through the channel. There is really nothing a CPU can do. We call these tasks IO-bound tasks. These include tasks such as
- reading/writing files
- network communications
- database queries
- user input/output
For all these tasks, it is waste of CPU cycles to simply sit and wait, if there are other tasks that need the CPU resource. This is when a coroutine would yield its control to those tasks that need the CPU resources.
Exercise
Learning the theory won’t be fun if we can’t apply it. Let’s build a mini clone of Apache Bench that benchmarks latency of a web server. The program will send multiple requests to a server and report average latency as well as size of the data in the response. For simplicity, let’s write in Python.
Below shows what we want to achieve with the program.
usage: mini ab [-h] [-n N] [-c C] [--coroutine] url
positional arguments:
url server url to send GET request
options:
-h, --help show this help message and exit
-n N total number of requests
-c C number of concurrent requests
--coroutine use coroutines instead of threads
First, let’s implement it without coroutine. To support concurrent requests, we need to make use of a ThreadPoolExecutor.
import argparse
import time
import requests
from typing import Tuple
from concurrent.futures import ThreadPoolExecutor
def send_request(url: str) -> Tuple[int, bytes]:
start = time.time()
response = requests.get(url)
end = time.time()
return end - start, response.content
def main():
parser = argparse.ArgumentParser("mini ab")
parser.add_argument('url', help='server url to send GET request')
parser.add_argument('-n', type=int, default=1, help='total number of requests')
parser.add_argument('-c', type=int, default=1, help='number of concurrent requests')
parser.add_argument('--coroutine', action='store_true', help='use coroutines instead of threads')
args = parser.parse_args()
if not args.coroutine:
with ThreadPoolExecutor(args.c) as e:
results = e.map(send_request, [args.url] * args.n)
else:
raise NotImplementedError()
latencies, data = zip(*results)
avg_latency = sum(latencies) / len(latencies)
avg_datasize = sum(map(lambda x: len(x), data)) / len(data)
print(f'average latency: {avg_latency*1000}ms')
print(f'average response size: {avg_datasize/1000}kB')
if __name__ == '__main__':
main()
The code should be straightforward. We maintain a pool of thread workers, and let each thread handle only one connection at a time. Let’s run a simple test
python ab.py -n100 -c10 https://www.crowdstrike.com/en-us/
average latency: 108.20968866348267ms
average response size: 152.551kB
So far so good. Now, let’s implement --coroutine option. aiohttp library supports asynchronous version of sending a request, so we can use it in place of requests. As for dispatching multiple coroutines, we can utilize Python standard library called asyncio. Finally, we use a semaphore to control maximum number of concurrent connections.
Alright, below shows coroutine implementation. Note that for simplicity, we won’t utilize a thread pool within the coroutine implementation, i.e., all coroutines will run on a single-thread.
--- before
+++ after
@@ -1,6 +1,8 @@
import argparse
import time
import requests
+import asyncio
+import aiohttp
from typing import Tuple
from concurrent.futures import ThreadPoolExecutor
@@ -10,6 +12,21 @@
end = time.time()
return end - start, response.content
+async def send_request_async(url: str, semaphore: asyncio.Semaphore) -> Tuple[int, bytes]:
+ async with semaphore:
+ start = time.time()
+ async with aiohttp.ClientSession() as session:
+ async with session.get(url) as response:
+ content = await response.read()
+ end = time.time()
+ return end - start, content
+
+async def main_async(url: str, n: int, c: int):
+ semaphore = asyncio.Semaphore(c)
+ tasks = [send_request_async(url, semaphore) for _ in range(n)]
+ results = await asyncio.gather(*tasks)
+ return results
+
def main():
parser = argparse.ArgumentParser("mini ab")
parser.add_argument('url', help='server url to send GET request')
@@ -22,7 +39,7 @@
with ThreadPoolExecutor(args.c) as e:
results = e.map(send_request, [args.url] * args.n)
else:
- raise NotImplementedError()
+ results = asyncio.run(main_async(args.url, args.n, args.c))
latencies, data = zip(*results)
avg_latency = sum(latencies) / len(latencies)
It is a bit more complex, but below summarizes some key take-aways
async defdenotes acoroutinewhereasdefdenotes asubroutine- the
awaitexpression represents the point where thecoroutineyields execution. Hence, you canawaitonly within acoroutine - to access the return value of a
coroutine, one mustawait(if within acoroutine) or callasyncio.run()(if not within acoroutine) semaphorecontrols number of concurrent accesses
You can find the full source code here.
Benchmark
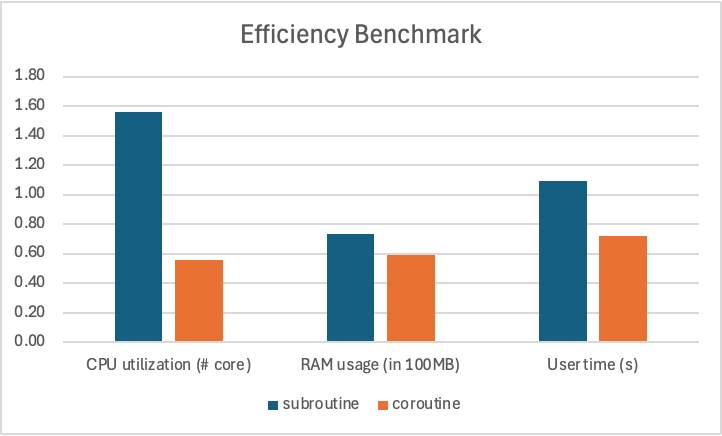
Now, let’s benchmark and verify whether using coroutines are indeed more efficient. For that, we will use /usr/bin/time -v to measure number of instructions.
# using subroutines and threads
/usr/bin/time -v python ab.py -c100 -n100 https://www.crowdstrike.com/en-us/
average latency: 341.6006636619568ms
average response size: 152.551kB
Command being timed: "python ab.py -c100 -n100 https://www.crowdstrike.com/en-us/"
User time (seconds): 1.09
System time (seconds): 0.31
Percent of CPU this job got: 156%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.89
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 73492
...
# using coroutines
/usr/bin/time -v python ab.py -c100 -n100 https://www.crowdstrike.com/en-us/ --coroutine
average latency: 439.5482325553894ms
average response size: 152.551kB
Command being timed: "python ab.py -c100 -n100 https://www.crowdstrike.com/en-us/"
User time (seconds): 0.72
System time (seconds): 0.11
Percent of CPU this job got: 56%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:01.48
Average shared text size (kbyes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 59
...
Below graph summarizes efficiency comparison with and without coroutines. We can see that the coroutine implementation requires less CPU resources, less RAM, and less user time (i.e., CPU time in user mode). Note that coroutines are efficient but does not run faster than thread pool implementation. In fact for the most effective server, one must use coroutines run on a thread pool.
subroutines with a thread pool vs coroutine on a single thread
Conclusion
Coroutines allow more efficient implementation of a program when it needs to process a large number of concurrent IO-bound tasks. In particular, coroutines can scale much better than threads, as they are much cheaper. In practice, coroutines are used along with multiple threads to implement scalable web servers.
References
- aiohttp: asynchronous HTTP client/server library for Python
- concurrent.futures - Launching parallel tasks: Python standard library docs for thread and process executors
- asyncio - Asynchronous I/O: Python standard library docs for
async/await - Semaphore (programming) - Wikipedia: overview of semaphores for concurrency control
- ab - Apache HTTP server benchmarking tool: Apache Bench reference