Speed up your server — 1
Let’s explore how to create a scalable and performant server. Though we will cover general techniques not specific to one particular…
Speed up your server — 1
Let’s explore how to create a scalable and performant server. Though we will cover general techniques not specific to one particular server or framework, we will use FastAPI and Uvicorn libraries as concrete examples. For this first sequel, we will discuss speeding up with coroutines or async functions.
Prerequisite
Install fastapi[standard] package for the server. We also need Apache HTTP server benchmarking tool for the client.
# server
pip install "fastapi[standard]"
# client
apt-get install apache2-utils
Baseline
Below is our baseline server implementation. The client will send a GET request with time in second, and the server will respond back after that the specified time.
# server.py
from fastapi import FastAPI
import time
app = FastAPI()
@app.get("/baseline/sleep/{n}")
def baseline_sleep(n: float):
time.sleep(n)
return f"hello world after {n}s of sleep"
Here, time.sleep() emulates latency due to light CPU workload, such as input/output operations. Now, let’s launch this server.
fastapi run server.py
Now that the server is running, let’s open up a terminal from a client and hammer the server with lost of concurrent requests. The easiest option is to use Apache HTTP server benchmarking tool. Let’s send total 1,000 requests with 100 concurrent requests to the server, emulating 0.1s of IO workload.
ab -n1000 -c100 -e output.csv SERVER_IP:8000/baseline/sleep/0.1
This will produce output.csv file containing cumulative distribution of the total time.
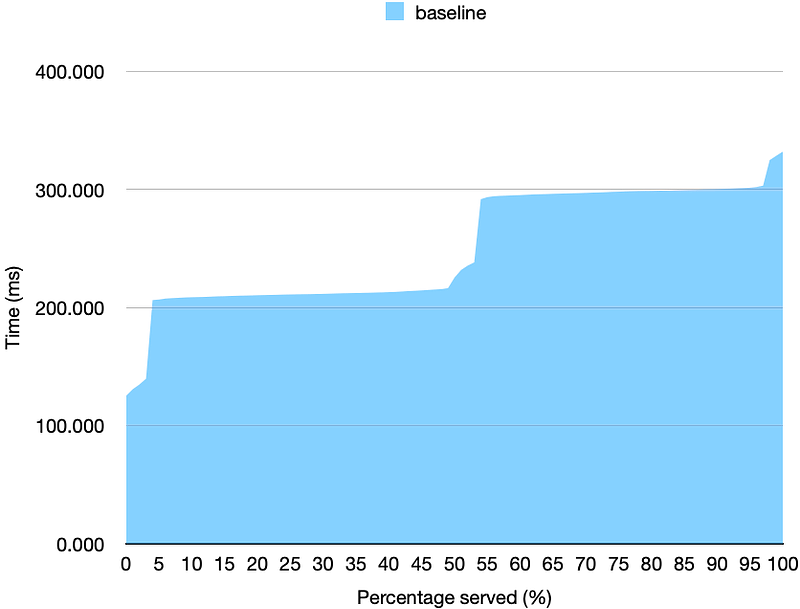
The ideal time for all of the requests would be 100ms (requested) + a few extra ms for communication latency between the server and client. However, we achieve p95 time of > 300ms, 3x more latency than ideal implementation.
Speed up with Async/Coroutine
The first technique is to employ coroutines to handle non-CPU-bound work, such as IO tasks. Most libraries should support async APIs if the task is IO-bound. For example, requests module only support synchronous/blocking APIs, whereas aiohttp module supports asynchronous/non-blocking APIs. As for our time.sleep(), we can replace with asyncio.sleep(). Let’s add a new endpoint.
--- before
+++ after
@@ -1,4 +1,5 @@
from fastapi import FastAPI
+import asyncio
import time
app = FastAPI()
@@ -7,3 +8,9 @@
def baseline_sleep(n: float):
time.sleep(n)
return f"hello world after {n}s of sleep"
+
+
@app.get("/async/sleep/{n}")
async def async_sleep(n: float):
await asyncio.sleep(n)
return f"hello world after {n}s of sleep"
Now, let’s re-run the server and re-benchmark using the new async endpoint.
ab -n1000 -c100 -e output.csv SERVER_IP:8000/asnyc/sleep/0.1
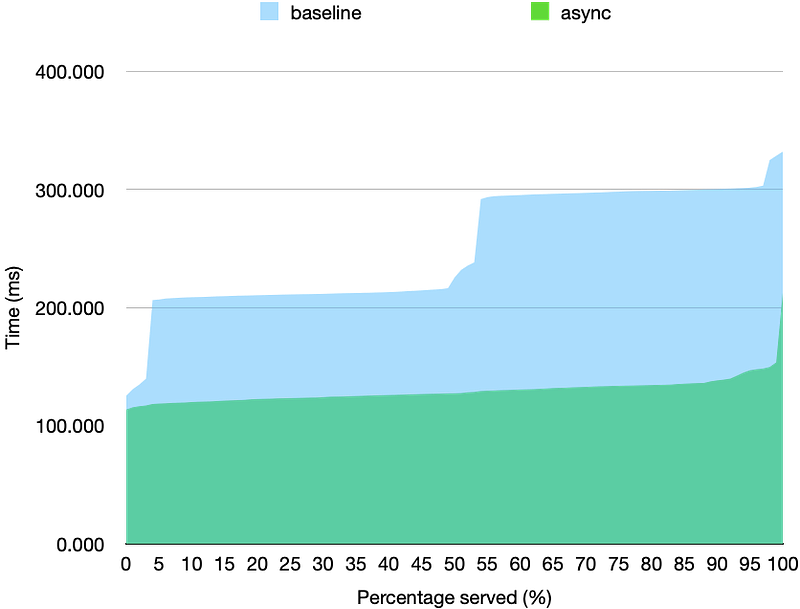
Hooray, the p95 latency has improved from ~300ms to ~150ms! That is 2x improvement from the baseline just from using coroutines.
This is all good, but there is a catch — some servers need to perform CPU-bound tasks, with which coroutine cannot help at all. That is what we will explore in the next article, so stay tuned!