Speed up your server — 3
In the previous articles, we explored how to speed up a server by employing coroutines and multiple workers. Today, we will explore how to…
Speed up your server — 3
In the previous articles, we explored how to speed up a server by employing coroutines and multiple workers. Today, we will explore how to serve with parallel coroutines working concurrently.
Baseline
As before, let’s start with the baseline. This time, we want to simulate both CPU-intensive task as well as IO-task. For that, we will combine fibo() and sleep() together.
# baseline.py
from fastapi import FastAPI
import time
app = FastAPI()
def fibo(n: int) -> int:
if n <= 1:
return n
return fibo(n - 2) + fibo(n - 1)
@app.get("/baseline/fibo_sleep/{n}")
def baseline_fibo_sleep(n: int):
x = fibo(n) / 1_000_000.0
time.sleep(x)
return f"hello after {x}s of sleep"
Let’s fire up the server and measure its latency.
ab -n1000 -c100 -e baseline.csv SERVER_IP:8000/baseline/fibo_sleep/20
Async
We can easily implement async version to take advantage of the IO-bound tasks.
--- baseline.py
+++ async.py
@@ -1,5 +1,6 @@
from fastapi import FastAPI
import time
+import asyncio
app = FastAPI()
@@ -15,3 +16,10 @@ def baseline_fibo_sleep(n: int):
x = fibo(n) / 1_000_000.0
time.sleep(x)
return f"hello after {x}s of sleep"
+
+
@app.get("/async/fibo_sleep/{n}")
async def async_fibo_sleep(n: int):
x = fibo(n) / 1_000_000.0
await asyncio.sleep(x)
return f"hello after {x}s of sleep"
Let’s now compare with the baseline.
ab -n1000 -c100 -e async.csv SERVER_IP:8000/async/fibo_sleep/20
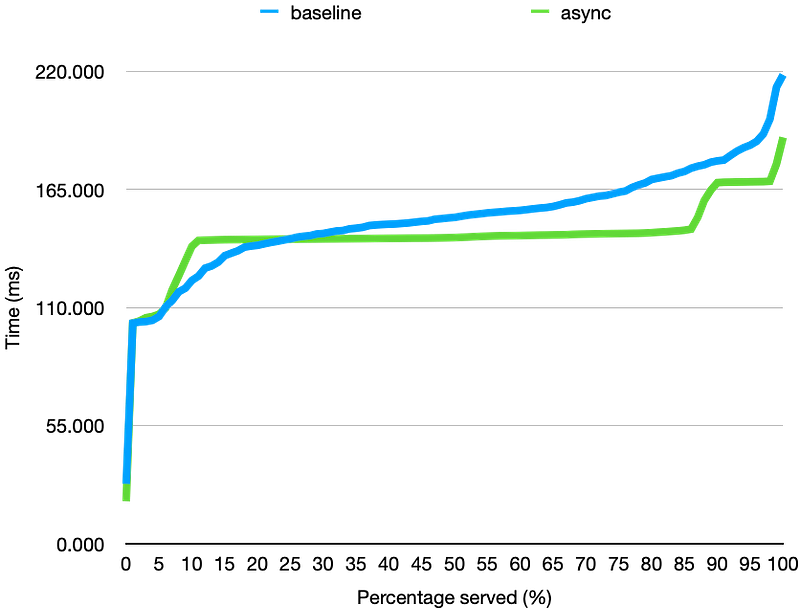
As we have seen before, running the coroutine does help with IO-bound work, but adds more overhead for CPU-bound work. We do see slight improvement over the baseline, but async itself does not help too much here due to the CPU-intensive work.
Parallelization
Let’s experiment with ProcessPoolExecutor to utilize multiple workers as before.
--- async.py
+++ par.py
@@ -1,8 +1,10 @@
from fastapi import FastAPI
import time
import asyncio
+from concurrent.futures import ProcessPoolExecutor
app = FastAPI()
+executor = ProcessPoolExecutor()
def fibo(n: int) -> int:
@@ -23,3 +25,11 @@ async def async_fibo_sleep(n: int):
x = fibo(n) / 1_000_000.0
await asyncio.sleep(x)
return f"hello after {x}s of sleep"
+
+
@app.get("/par/fibo_sleep/{n}")
async def par_fibo_sleep(n: int):
loop = asyncio.get_event_loop()
x = await loop.run_in_executor(executor, fibo, n) / 1_000_000.0
await asyncio.sleep(x)
return f"hello after {x}s of sleep"
Let’s again run the benchmark
ab -n1000 -c100 -e par.csv SERVER_IP:8000/par/fibo_sleep/20
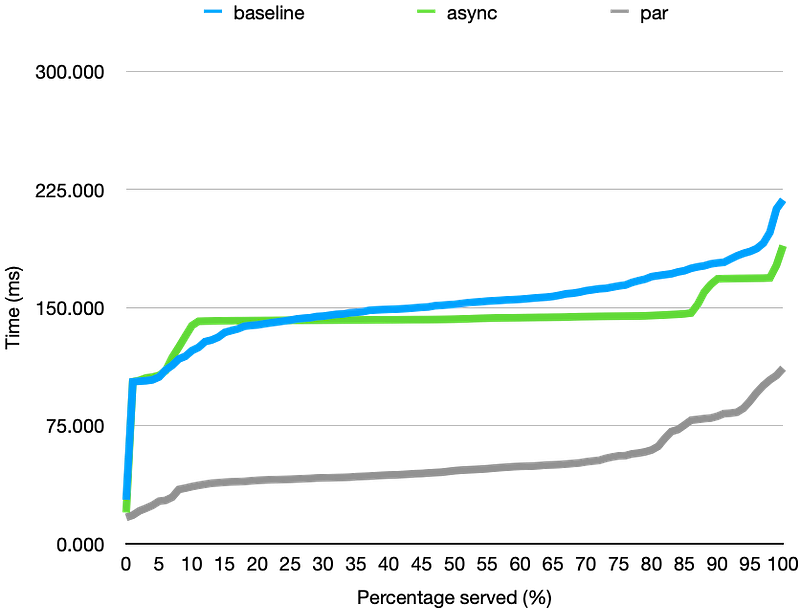
Utilizing multiple works definitely help throughput of the server. However, there is one thing to note. The graph of the parallel implementation looks similar to baseline rather than async. This is because we are only parallelizing the CPU-bound work, i.e., fibo() but not the IO-bound work, i.e., sleep() . It would be even better if we could parallelize all work, right?
Parallel Coroutines
Most server framework support parallel workers out of the box. For FastAPI, which delegates the server deployment to Uvicorn, we can simply pass --workers parameter to instantiate multiple identical servers. What this will do is creating multiple identical processes of the server running independently. The parent process will simply send the task to one of the workers.
If worker process has its own event loop to run coroutines concurrently. Hence, this allows us parallelize not only a fibo() but also sleep(). Let’s re-run the async implementation, but this time simply supply --workers parameter with the number of cores the system has, say 6.
fastapi run --workers=6 async.py
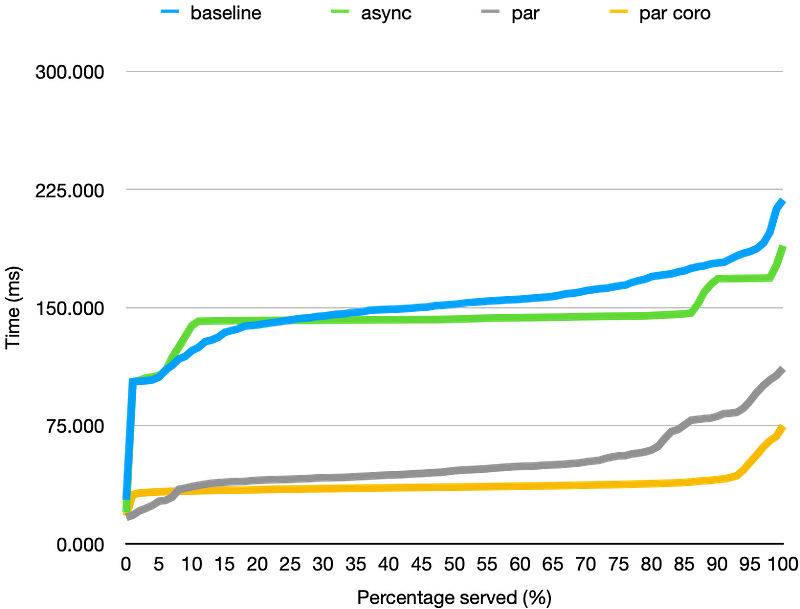
Finally, we get the best result. By parallelizing all work, we are able to reduce the p95 latency from ~90s to ~50s. Not only is this easier than our manual parallel implementation but also more efficient!
Conclusion
So, we will conclude our exploration here with the following lessons to juice every droplet from the server
- if any IO-bound task is present, use a coroutine
- don’t manually parallelize the work yourself — your server framework most likely already supports parallelization out of the box
But more importantly, always benchmark your server!