Anatomy of gzip—compression data bits and pieces
Gzip is one of the most popular lossless data compression format used among non-Windows users. It is based on Lempel–Ziv coding, aka, LZ77. Ordinary data is represented as a stream of bytes. With LZ77 coding, the stream of bytes is converted into a stream of LZ77 codes where each code is either one of
- a
Literal, representing a single byte Length/Distancepair
A Literal code is the same as a byte. The Length/Distance pair points to the previous location in the stream with the same bytes of the specified length. Typical human generated data are not random and contains many repetitions of bytes, and hence this representation is extremely simple yet effective. Virtually all popular data compression methods are based on LZ77, e.g., gzip, xz, zstd, and brotli.
Today, we are going to study how data compression is achieved and distrusted across different components. For technical details of gzip compression, refer to RFC1951.
Entropy Estimation
I ran gzip on the first 10MB of Linux source tarball file, which resulted in 2.4MB, about 24% compression ratio. I then collected all Lz77 codes within each DEFLATE block of the compressed data. From the distribution of each code, we can estimate the probability of each code appearing and hence the entropy and theoretical bits need to encode. For simplicity, I used a unigram model, i.e., the probability of each code is context-independent and constant across the block. Below shows Literal code histogram.
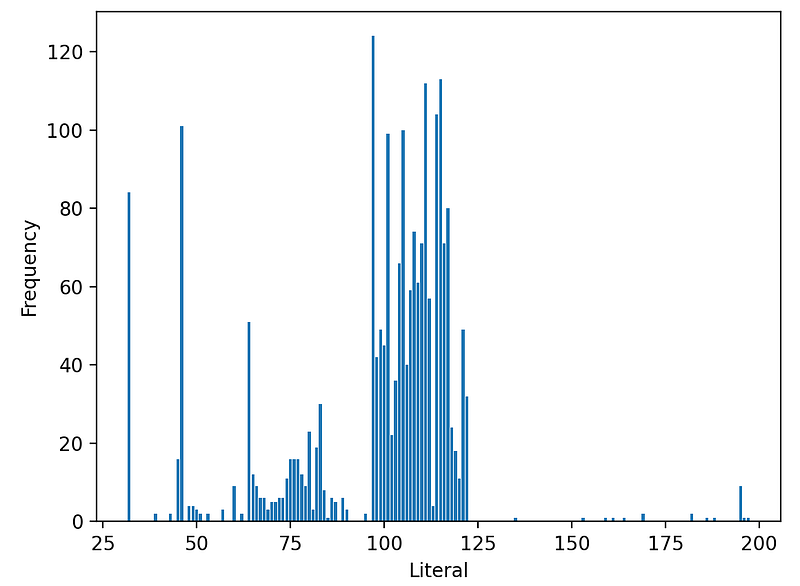
Note that there are few occurrences above 127, as this is a tarball of mostly ASCII text files. For example, the Literal value with the highest count is 97, which corresponds to a character. Using the unigram model, we can estimate the probability of the Literal code a to be p = 124 / 2114 = 0.058, whose entropy then becomes -log2(p) = 4.1 bits. Adding the entropy from each Literal code for each occurrence, we can estimate the entropy from the entire Literal codes.
Similarly, I did the same for Length and Distance codes as well.
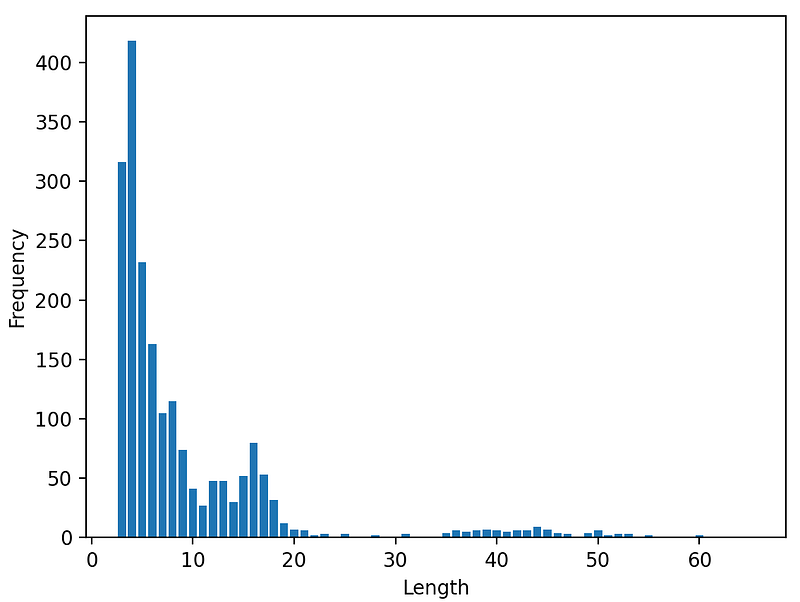
Literal or Length
 Figure: Lz77 decoding algorithm
Figure: Lz77 decoding algorithm
When we decode these codes, there is one more category of code required. That is, the decoder must know whether the current symbol is going to be a Literal or Length/Distance pair. This information has to be encoded first. In DEFLATE, they combine Literal and Length codes into a single codebook, but we don’t have to. Let’s assume we encode a binary code for this. We can calculate entropy of this, just like any other codes.
Codebook and Other
We are almost there, but there one more big chunk of data that needs to be encoded — the codebook or the model. In case Huffman coding is used, it is called the codebook. When range-coding or arithmetic coding is used, it is called the model or probability table. The decoder needs to know this a priori to be able to decode the symbols correctly.
Of course, the codebook itself takes up considerable amount of data, so in DEFLATE the codebook itself is compressed. As for encoding the probability table, there is a trade off — higher precision in probability leads to better compression from the entropy coding but larger overhead from the table itself.
Finally, there are some additional bits that we need to account for, such as overhead from imperfect entropy coding, data from header/footer, and misc. things like end-of-block indicator, etc.
Putting it all together
Here is the final result. Below pie chart shows the breakdown of all the components that go into a .gz file.
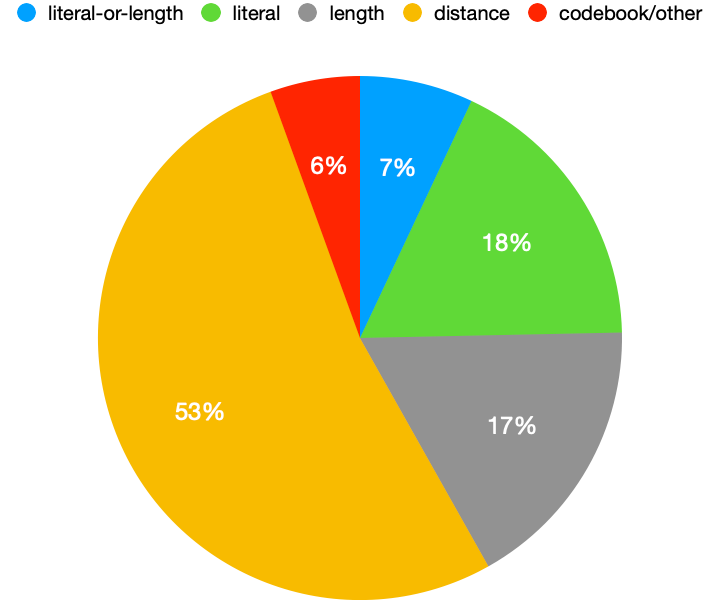
Some interesting observations
distancecodes take up the most, more than 50%. This is because there is a lot of repetition within the data that is compressed.length/distanceoccur in pair, butdistancetakes up 3x more bits thanlengthbecausedistanceranges from 1 to 32768 whilelengthranges from 3 to 258.- codebook/other takes up only 6%, which is lower than I expected. Recall that this includes the data needed to encode literal/length/distance codebook + inefficiency from Huffman coding. This implies that we can’t squeeze out much juice by replacing Huffman coding with more efficient entropy coding, such as range coding. Even if we achieve perfect entropy coding and somehow magically encode the full-precision probability tables for free, we can only achieve 6% reduction in size compared to the
gzipcompressed file. Assuming 4x compression fromgzip, that would account for only 1.5% reduction from the original file size. - one obvious opportunity to improve compression ratio would be to somehow reduce
distancesegment, as it takes up the majority of the bits. Another approach would be to use better model than unigram for probability estimation. This is whatxzdoes with its LZMA.
I also calculated average number of bits each code consumes (disregarding codebook/others)
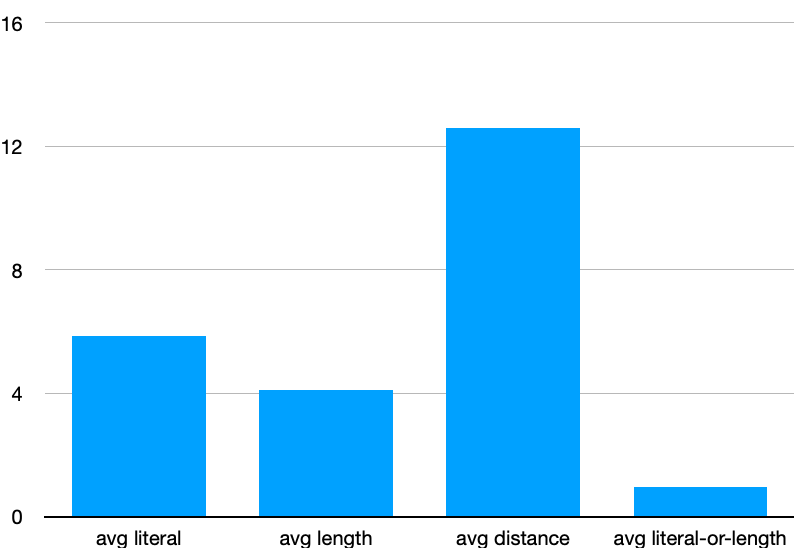
Each literal consumes about 6-bits, which is reasonable in that it would take up exactly 8-bits without compression. Each length consumes about 4-bits, again reasonable because there is a high probability density for < 20. Each distance consumes about 13-bits, again reasonable as it could take up to 15-bits to represent up to 32768. Finally, literal-or-length takes up a bit less than 1-bit (no pun intended) — it would take exactly 1-bit if completely random.
Note that this clearly tells us that it is much better (cheaper) to encode with two literal codes than length/distance pair up to length ≤ 2, and it is comparable for length of 3. For length ≥ 4, it is better to encode with length/distance pair than literals.
If you are interested in learning how gzip works under the hood, I have written a series of articles on writing gzip decompression from scratch. Also, feel free to checkout this repo.
References
- Gzip - GNU Project - Free Software Foundation
- XZ Utils
- GitHub - facebook/zstd: Zstandard - Fast real-time compression algorithm
- GitHub - google/brotli: Brotli compression format
- Lempel-Ziv-Markov chain algorithm explained
- RFC 1951: DEFLATE Compressed Data Format Specification version 1.3