Performance optimization—efficient cache programming 1
Last time, we have examined a real example of branchless programming technique, which resulted in 7x speed up by reducing branch misses. Today, let’s explore how to speed up by employing efficient cache programming techniques again by looking at real examples and running benchmark. You can find the full source code here.
If you are not already familiar with this topic, I strongly recommend this classic video for excellent introduction.
Accessing memory is extremely slow in comparison to modern CPU’s performance. For this reason, modern CPUs are equipped with multiple levels of cache to speed up accessing data from memory. Large cache makes significant difference in computing power, especially those application that require large memory, such as games.
Below is L1/L2/L3 cache size of AMD’s Ryzen 9800X3D. Having very large L3 cache (96MB) is the reason why this CPU is the best gaming CPU as of today.
| Cache Level | Cache Size |
|---|---|
| L1 | 640KB |
| L2 | 8MB |
| L3 | 96MB |
Given limited size of cache, the best thing we could do is to optimize the program to use the cache as efficiently as possible. This typically corresponds to reducing the memory usage as much as possible. Let’s write the following program in different ways to see how to achieve the speed up. Try it yourself too!
Programming Task
Suppose we need to compute a hash value through a series of operations, either “add” or “multiply,” using values between 1 and 32768 (inclusive). Each operation is serialized as a JSON object of type:
enum Code {
Multiply(u16), // 1..32768
Add(u16), // 1..32768
}
The process involves two main steps:
-
Codebook Creation:
- Read an integer
nfrom the input as a string. - Read
nlines of JSON objects to create the codebook.
- Read an integer
-
Operation Execution:
- Initialize with
0u64 - Read 4-byte
u32operation ID from the input. - Look up operation in the codebook using its ID.
- Perform the corresponding operation
- Repeat until end of file
- Initialize with
Here is a simple example input:
4
{"Add":32740}
{"Multiply":761}
{"Multiply":30965}
{"Add":5}
\x00000001\x00000000\x00000010\x00000011\0x00000001
This input indicates:
- A codebook with 4 operations
- Execution order: operations 1, 0, 2, 3, 1
The expected output of the program by running this input is ((0 * 761 + 32749) * 30965 + 5) * 761 = 771709393190
Before optimization
I’d implement the program as follows. The hotspot would be run() function that looks up the operation from the codebook and execute.
use serde::{Deserialize, Serialize};
use std::io::{self, stdin, BufRead, Read};
#[derive(Serialize, Deserialize)]
enum Operation {
Multiply(u16), // 1..32768
Add(u16), // 1..32768
}
fn main() -> io::Result<()> {
let mut handle = stdin().lock();
let mut lines = handle.by_ref().lines();
// Read n
let n: u32 = lines.next().unwrap()?.parse().unwrap();
// Read n Code elements
let mut codebook = Vec::with_capacity(n as usize);
for _ in 0..n {
let line = lines.next().unwrap()?;
let code: Operation = serde_json::from_str(&line).unwrap();
codebook.push(code);
}
// Read code until EOF
let mut buf = Vec::new();
handle.read_to_end(&mut buf)?;
let indices: &[u32] = from_u8(&buf);
let result = run(&codebook, indices);
println!("{}", result);
Ok(())
}
fn run(codebook: &[Operation], indices: &[u32]) -> u64 {
indices
.iter()
.fold(0, |acc, ix| match codebook[*ix as usize] {
Operation::Multiply(x) => acc.wrapping_mul(x as u64),
Operation::Add(x) => acc.wrapping_add(x as u64),
})
}
fn from_u8<T>(arr: &[u8]) -> &[T] {
let item_size = std::mem::size_of::<T>();
assert_eq!(arr.len() % item_size, 0);
let len = arr.len() / item_size;
let ptr = arr.as_ptr() as *const T;
unsafe { std::slice::from_raw_parts(ptr, len) }
}
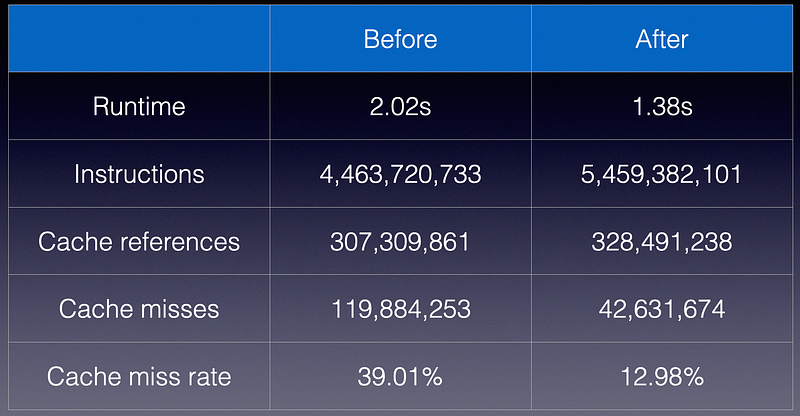
Running this on a codebook of size 1,000,000 and 200,000,000 operations, I get around 2s of runtime.
4,463,720,733 instructions
828,230,183 branches
2,193,853 branch-misses # 0.26% of all branches
307,309,861 cache-references
119,884,253 cache-misses # 39.01% of all cache refs
2.019265986 seconds time elapsed
1.561133000 seconds user
0.458039000 seconds sys
After optimization
Now, let’s try to improve our implementation. First notice how cache-misses is whopping 39% above. This is definitely something we should reduce in order to achieve performance gain. Whenever we are dealing with an array of elements, the first thing to try is to reduce the memory size of the array as much as possible. This will reduce memory footprint and hence cache-miss rate.
In fn run(codebook: &[Operation], indices: &[u32]) -> u64 function, we can’t do much with indices: &[u32] since that is specification. What we could modify is codebook: &[Operation]. Let’s observe how many bytes Operation is. From Rust playground, we can see it takes up 4 bytes. Can we do better?
Looking at the range, the operand of Add and Multiply variants are 1 to 32768, meaning 2¹⁵ each. Hence, a single u16 can represent any Operation as follows
struct CompactOperation(u16);
impl CompactOperation {
const MASK: u16 = 1 << 15;
const MULTIPLY: u16 = 1 << 15;
const ADD: u16 = 0 << 15;
}
impl From<Operation> for CompactOperation {
fn from(value: Operation) -> Self {
match value {
Operation::Multiply(x) => CompactOperation((x - 1) | Self::MULTIPLY),
Operation::Add(x) => CompactOperation((x - 1) | Self::ADD),
}
}
}
We let the left-most bit indicate whether Add or Multiply operation, and the rest of 15-bits represent the operand 1 to 32768 minus 1. We are essentially creating the enum but more efficiently. Now, CompactOperation struct is only u16, so that is 2-bytes large. This will reduce the memory size of the codebook array by half. How much of performance impact can this have? Below shows the diff for the new implementation after cache optimization
--- before
+++ after
@@ -7,6 +7,24 @@
Add(u16), // 1..32768
}
+#[derive(Copy, Clone)]
+struct CompactOperation(u16);
+
+impl CompactOperation {
+ const MASK: u16 = 1 << 15;
+ const MULTIPLY: u16 = 1 << 15;
+ const ADD: u16 = 0 << 15;
+}
+
+impl From<Operation> for CompactOperation {
+ fn from(value: Operation) -> Self {
+ match value {
+ Operation::Multiply(x) => CompactOperation((x - 1) | Self::MULTIPLY),
+ Operation::Add(x) => CompactOperation((x - 1) | Self::ADD),
+ }
+ }
+}
+
fn main() -> io::Result<()> {
let mut handle = stdin().lock();
let mut lines = handle.by_ref().lines();
@@ -19,7 +37,7 @@
for _ in 0..n {
let line = lines.next().unwrap()?;
let code: Operation = serde_json::from_str(&line).unwrap();
- codebook.push(code);
+ codebook.push(CompactOperation::from(code));
}
// Read code until EOF
@@ -32,13 +50,16 @@
Ok(())
}
-fn run(codebook: &[Operation], indices: &[u32]) -> u64 {
- indices
- .iter()
- .fold(0, |acc, ix| match codebook[*ix as usize] {
- Operation::Multiply(x) => acc.wrapping_mul(x as u64),
- Operation::Add(x) => acc.wrapping_add(x as u64),
- })
+fn run(codebook: &[CompactOperation], indices: &[u32]) -> u64 {
+ indices.iter().fold(0, |acc, ix| {
+ let compact_code = codebook[*ix as usize];
+ let x = (compact_code.0 & !CompactOperation::MASK) as u64 + 1;
+ match compact_code.0 & CompactOperation::MASK {
+ CompactOperation::MULTIPLY => acc.wrapping_mul(x),
+ CompactOperation::ADD => acc.wrapping_add(x),
+ _ => unreachable!(),
+ }
+ })
}
fn from_u8<T>(arr: &[u8]) -> &[T] {
Again, not much change from the original version. We are just manually implementing enum but more compactly. Running this modified version using the same input, I get
5,459,382,101 instructions
827,363,852 branches
2,196,592 branch-misses # 0.27% of all branches
328,491,238 cache-references
42,631,674 cache-misses # 12.98% of all cache refs
1.384393534 seconds time elapsed
0.931324000 seconds user
0.452671000 seconds sys
Note that the benchmark result may vary greatly depending on the cache size and speed of the system used.
First, notice the cache-miss rate is now reduced from 39% to 13%. However, there is also 20% increase in instructions from 4.4B to 5.5B probably because of extra work required to convert from Operation to CompactOperation in the codebook. Despite this, the **performance increased by 1.4x ** just by reducing the memory footprint of the array!
Alright, so the lesson of this article is to reduce memory footprint of an array. This implies that relying on high-level abstraction such as std::variant for C++ and enum for Rust isn’t always the most efficient implementation. Obviously, this does not mean you should never use them, but it just means there are times where it is better to manually re-implement.
Another example is a struct with multiple fields that can also be compacted into a smaller-size data type. Here is one such example from the real world (DEFLATE) that bit-packs the following 8-bytes struct into 4-bytes.
// 8-bytes
struct Data {
extra_bits: u8, // 0..=13
value: u16, // 0..=24577
codelength: u8, // 0..=15
symbol: u16, // 0..=285
}
// 4-bytes
// extra_bits: 4-bits | value: 15-bits | codelength: 4-bits | symbol: 9-bits
struct PackedData(u32);
We will not go through this example here, as it shall yield similar result. Suffice to say that *when you have a large array of objects to enumerate, make sure the object footprint is as compact as possible!