Performance optimization — efficient cache programming 2
In the previous article, we explored how reducing memory size of an array significantly improved runtime performance by improving cache-hits. Today, we will explore another way to boost performance of programming just by rearranging nested loops by optimal use of cache line, resulting in 7x speed gain!
You can find the full source code here.
A cache line is the smallest unit of data transferred between cache and main memory. When accessing a single byte, the entire cache line containing that byte is loaded. This mechanism leverages spatial locality, as nearby data is likely to be accessed soon. For optimal performance, accessing array elements sequentially aligns with cache line loading, maximizing cache utilization. However, some operations inadvertently access memory non-contiguously, leading to performance degradation. Matrix multiplication is a prime example of this issue.
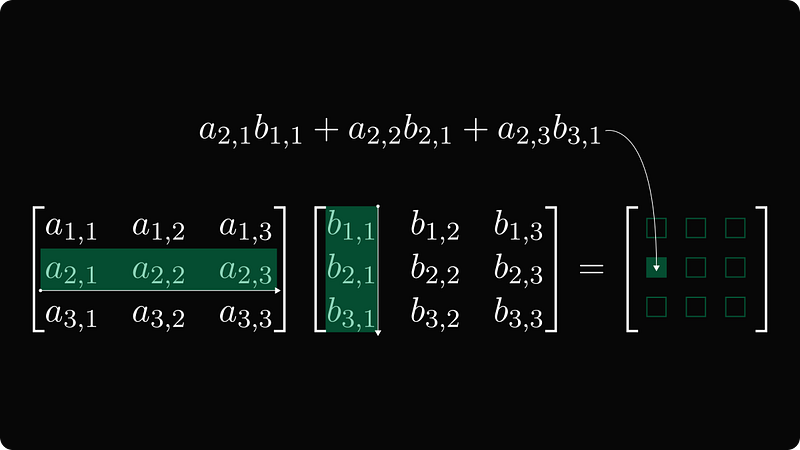
https://www.linkedin.com/pulse/matrix-multiplication-explained-tivadar-danka
This is how we learn to perform matrix multiplication. Suppose two matrices U and V whose dimensions are i,k and k,j are given. The product has dimension i,j where
- element at row
iandjis the sum over element-wise product ofU’sith row andV’sjth column.
In code, the matrix multiplication involves 3-level nested loops
for i in 0..nrows {
for j in 0..ncols {
for k in 0..u.ncols {
*prod.at_mut(i, j) += u.at(i, k) * v.at(k, j);
}
}
}
The most-inner loop calculates the element value at position i,j . When I run a simple 1000 x 1000 matrix multiplication (where SIMD is disabled), here is what I get
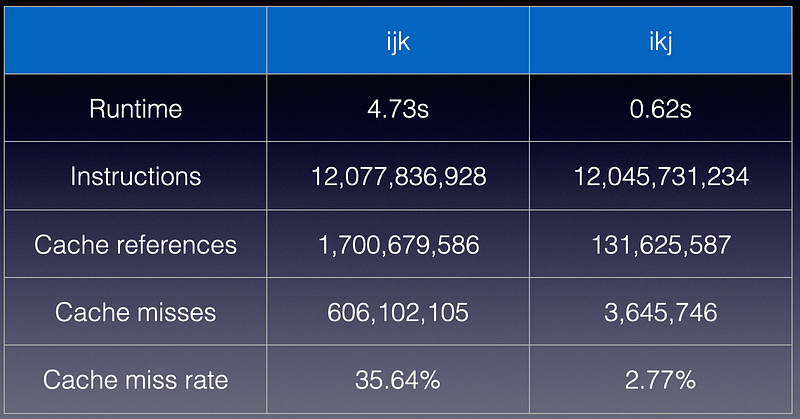
12,077,836,928 instructions
1,700,679,586 cache-references
606,102,105 cache-misses # 35.64% of all cache refs
3,015,861,870 branches
2,705,050 branch-misses # 0.09% of all branches
4.732371331 seconds time elapsed
4.705028000 seconds user
0.013994000 seconds sys
Notice that cache miss is whopping 35%, suggesting that there is an issue with the implementation.
The problem is, as I have stated before, we are not accessing elements in the matrix array sequentially. A matrix is represented as a flattened 1D array. In typical implementation, this means elements within a row are contiguous in memory but elements in a column are not. Notice that the inner-most loop goes through elements within V’s column, whose elements are not stored contiguous in memory.
for k in 0..u.ncols {
*prod.at_mut(i, j) += u.at(i, k) * v.at(k, j)
}
What if we flatten the 2D matrix data so that each column represents a contiguous memory? Well, that won’t work either because then U’s row is non-contiguous.
The solution is quite simple; we just need to rearrange the loops. That is, rather than doing ijk nested loop, we could do ikj loop.
--- ijk
+++ ikj
@@ -1,6 +1,6 @@
for i in 0..nrows {
- for j in 0..ncols {
- for k in 0..u.ncols {
+ for k in 0..u.ncols {
+ for j in 0..ncols {
*prod.at_mut(i, j) += u.at(i, k) * v.at(k, j);
}
}
Now, the inner-most loop access elements in the product’s row and V’s row, so this shall be much more cache-friendly. Let’s verify by compiling (without SIMD) and running the benchmark
12,045,731,234 instructions
131,625,587 cache-references
3,645,746 cache-misses # 2.77% of all cache refs
3,008,907,790 branches
1,780,273 branch-misses # 0.06% of all branches
0.617420591 seconds time elapsed
0.604438000 seconds user
0.012987000 seconds sys
As expected, this implementation significantly runs 7.5x faster than the previous implementation with very similar number of instructions. Not only did the cache-miss rate reduced by 10x from 35% to 3%, but also the cache-references reduced by another 10x, resulting in > 100x fewer cache miss counts. All of this change from a simple loop rearrangement!
So, the moral of the story is that a good developer needs to understand the low-level in order to unlock true performance of software.