I was writing a simple program that reads in a database text file and groups rows by its id. I first wrote it in Python as I was lazy, and then I wrote it in Rust just to see how much speed gain I could obtain. Surprisingly, the two had almost the same runtime speed.
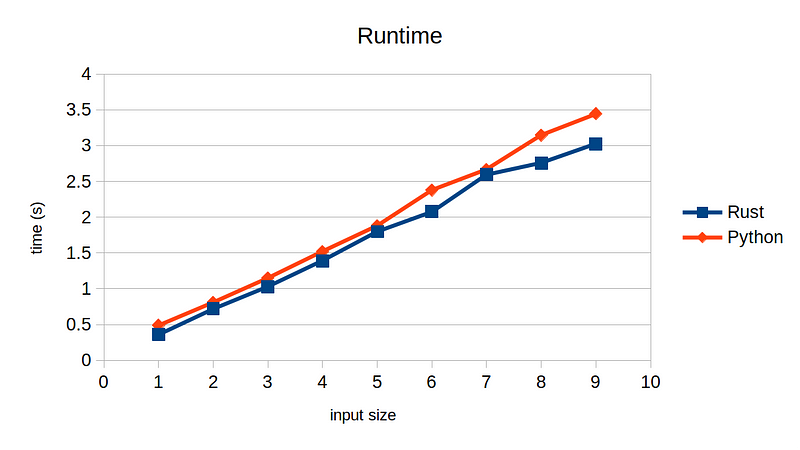
Though I didn’t intend to write the most efficient code, this still implied that I wrote a terribly inefficient code in Rust. I had to figure out what I have done wrong.
Maybe it is easier to start off with what the program should do. All it does is to group entries by the first column (ID). For simplicity, let’s assume the input is already sorted by the first column.
# input
id1 x1 y1
id1 x2 y2
id1 x3 y3
id2 a1 b1
id3 u1 v1
id3 u2 v2
# expected output
id1 x1,x2,x3 y1,y2,y3
id2 a1 b1
id3 u1,u2 v1,v2
OK, so now we know what to expect, let’s look the Python implementation:
import argparse
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--output", default="/dev/stdout")
args = parser.parse_args()
delim = "\t"
separator = ","
vec_tokens = []
id = None
with open("/dev/stdin", 'r') as r, \
open(args.output, 'w') as w:
for line in r:
tokens = line[:-1].split(delim)
if id is not None and id != tokens[0]:
xs = map(lambda xs: separator.join(xs), zip(*vec_tokens))
w.write(f"{id}{delim}{delim.join(xs)}\n")
vec_tokens.clear()
id = tokens[0]
vec_tokens.append(tokens[1:])
if vec_tokens:
xs = map(lambda xs: separator.join(xs), zip(*vec_tokens))
w.write(f"{id}{delim}{delim.join(xs)}\n")
Nothing fancy here. Note zip(*xs) performs a transpose in Python, which simplifies the code greatly. Now, let’s consider Rust implementation:
use std::fs::File;
use std::io::{stdin, BufRead, BufReader, BufWriter, Write};
use clap::Parser;
#[derive(Parser)]
struct Cli {
#[arg(long)]
output: Option<String>,
}
fn main() -> std::io::Result<()> {
let delimiter = "\t";
let separator = ",";
let cli = Cli::parse();
let output = cli.output.unwrap_or("/dev/stdout".to_owned());
let ifs = BufReader::new(stdin());
let mut ofs = BufWriter::new(File::create(output)?);
let mut cols: Vec<Vec<String>> = Vec::new();
let mut id = None;
for line in ifs.lines() {
let line = line?;
let mut tokens = line.split(delimiter);
let new_id = tokens.next().expect("invalid input");
if let Some(ref s) = id {
if s == new_id {
for (token, col) in tokens.zip(cols.iter_mut()) {
col.push(token.to_owned());
}
} else {
writeln!(
ofs,
"{}{}{}",
s,
delimiter,
cols.into_iter()
.map(|col| col.join(separator))
.collect::<Vec<_>>()
.join(delimiter)
)?;
id = Some(new_id.to_owned());
cols = tokens.map(|token| Vec::from([token.to_owned()])).collect();
}
} else {
id = Some(new_id.to_owned());
cols = tokens.map(|token| Vec::from([token.to_owned()])).collect();
}
}
if !cols.is_empty() {
writeln!(
ofs,
"{}{}{}",
id.unwrap(),
delimiter,
cols.into_iter()
.map(|col| col.join(separator))
.collect::<Vec<_>>()
.join(delimiter)
)?;
}
Ok(())
}
Maybe not the most elegant piece of code, but it does the job right. Since Rust does not offer built-in function that does a transpose, this manually does it by appending each token into the column vector.
Now, do you see any problem with this implementation? If you can accurately guess, you must be one of the performance expert! Anyways, I wasn’t really able to tell, so I ran Flamegraph.
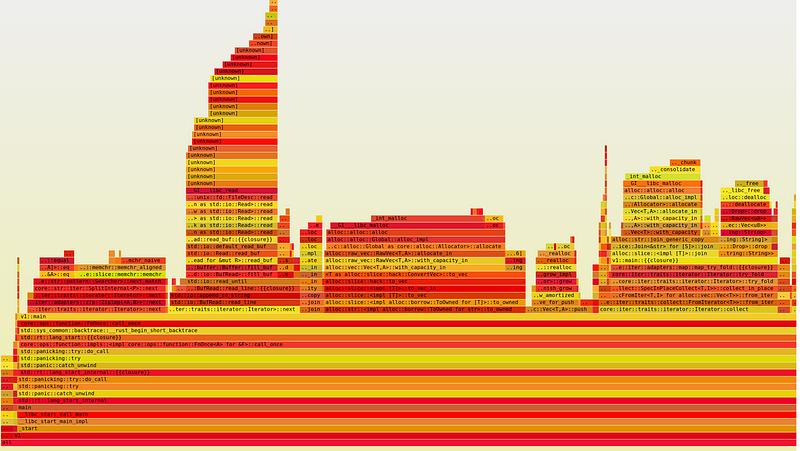
I noticed that in the middle, there is a very large chunk consuming 1/4 of the total runtime, which reads ToOwned for str. This is when I realized that I probably don’t want Vec<Vec<String>>, which is essentially a 3-level nested heap allocation.
Not only that, there is another large chunk of time spent on dynamic allocation and de-allocation resulting from Join<&str> function on the right-side of the graph.
With these information, I went ahead and refactored the Rust implementation a bit. Rather than storing a vector tokens and then call join, I manually built the joined column one by one as I read in each line, eliminating dynamic allocation of individual tokens, except for the first line for each ID.
let ifs = BufReader::new(stdin());
let mut ofs = BufWriter::new(File::create(output)?);
- let mut cols: Vec<Vec<String>> = Vec::new();
+ let mut cols: Vec<String> = Vec::new();
let mut id = None;
for line in ifs.lines() {
let line = line?;
@@ -28,39 +28,22 @@
if let Some(ref s) = id {
if s == new_id {
for (token, col) in tokens.zip(cols.iter_mut()) {
- col.push(token.to_owned());
+ *col += separator;
+ *col += token;
}
} else {
- writeln!(
- ofs,
- "{}{}{}",
- s,
- delimiter,
- cols.into_iter()
- .map(|col| col.join(separator))
- .collect::<Vec<_>>()
- .join(delimiter)
- )?;
+ writeln!(ofs, "{}{}{}", s, delimiter, cols.join(delimiter))?;
id = Some(new_id.to_owned());
- cols = tokens.map(|token| Vec::from([token.to_owned()])).collect();
+ cols = tokens.map(|s| s.to_owned()).collect();
}
} else {
id = Some(new_id.to_owned());
- cols = tokens.map(|token| Vec::from([token.to_owned()])).collect();
+ cols = tokens.map(|s| s.to_owned()).collect();
}
}
if !cols.is_empty() {
- writeln!(
- ofs,
- "{}{}{}",
- id.unwrap(),
- delimiter,
- cols.into_iter()
- .map(|col| col.join(separator))
- .collect::<Vec<_>>()
- .join(delimiter)
- )?;
+ writeln!(ofs, "{}{}{}", id.unwrap(), delimiter, cols.join(delimiter))?;
}
Ok(())
The code itself is now considerably simpler than before. How about performance?
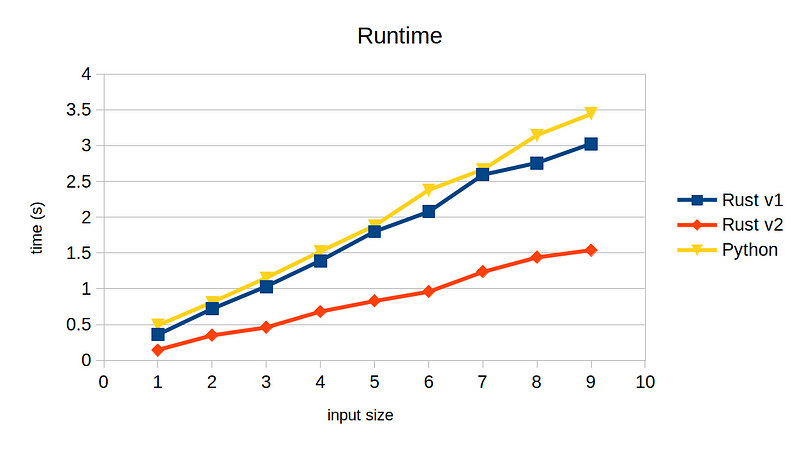
The runtime reduced to 50% with this simple change. Notice how the aforementioned chunks are gone. Instead, we now have on the left-end new chunk for append_elements, which comes from manually joining the tokens for each column. This new block, however, is consuming much less time compared to the ones removed, resulting in 2x performance gain.

So, the lesson is that dynamic allocation is quite expensive. The source code is available here.