If you are familiar with C++ or Rust, you are probably aware that static dispatch is more efficient than dynamic dispatch. Have you wondered exactly how much more efficient?
Well, let’s measure the difference in # instructions as well as runtime. Below is a simple program that counts # of tokens for each line of the input.
// ntoken
use clap::{Parser, ValueEnum};
use std::fs::File;
use std::io::{BufRead, BufReader, Result};
#[derive(Parser)]
#[command(name = "ntokens")]
#[command(author = "TechHara")]
#[command(version = "0.1.0")]
#[command(about = "print out number of tokens in each line", long_about = None)]
struct Cli {
/// select delimiter
#[arg(value_enum, long)]
delimiter: Delimiter,
/// select dispatch
#[arg(value_enum, long)]
dispatch: Dispatch,
/// Input file
input: Option<String>,
}
#[derive(ValueEnum, Clone, Copy)]
enum Delimiter {
Tab,
Whitespace,
}
#[derive(ValueEnum, Clone, Copy)]
enum Dispatch {
Static,
Dynamic,
}
fn main() -> Result<()> {
let args = Cli::parse();
let input_file = args.input.unwrap_or("/dev/stdin".to_owned());
let ifs = BufReader::new(File::open(input_file)?);
match args.dispatch {
Dispatch::Static => run_static_dispatch(args.delimiter, ifs),
Dispatch::Dynamic => run_dynamic_dispatch(args.delimiter, ifs),
}
}
fn static_dispatcher(
tokenize_and_count: impl Fn(String) -> usize,
ifs: BufReader<File>,
) -> Result<()> {
ifs.lines()
.map(|line| tokenize_and_count(line.unwrap()))
.for_each(move |n| {
println!("{n}");
});
Ok(())
}
fn run_static_dispatch(delim: Delimiter, ifs: BufReader<File>) -> Result<()> {
match delim {
Delimiter::Tab => static_dispatcher(|line| line.split('\t').count(), ifs),
Delimiter::Whitespace => static_dispatcher(|line| line.split_whitespace().count(), ifs),
}
}
fn run_dynamic_dispatch(delim: Delimiter, ifs: BufReader<File>) -> Result<()> {
let tokenize: Box<dyn for<'a> Fn(&'a str) -> Box<dyn Iterator<Item = &'a str> + 'a>> =
match delim {
Delimiter::Tab => Box::new(move |line| Box::new(line.split('\t'))),
Delimiter::Whitespace => Box::new(move |line| Box::new(line.split_whitespace())),
};
ifs.lines()
.map(|line| tokenize(&line.unwrap()).count())
.for_each(move |n| {
println!("{n}");
});
Ok(())
}
The user needs to specify whether the tokens are separated by a single TAB character or contiguous white-space characters. The program above handles the user’s request by either static dispatch or dynamic dispatch implementation.
Let’s examine the # instructions from running these two implementations. For that, we will use perf.
for n in `seq 10`; do perf stat -e instructions ./target/release/ntokens --dispatch static --delimiter tab input_$n.tsv 2>&1 | grep instructions | gawk '{print $1}' ; done
323040689
643661352
959290347
1278536597
1601217096
1922620963
2237266610
2568900462
2892550246
3212345136
for n in `seq 10`; do perf stat -e instructions ./target/release/ntokens --dispatch dynamic --delimiter tab input_$n.tsv 2>&1 | grep instructions | gawk '{print $1}' ; done
398722117
797494008
1192300879
1592327362
1989696872
2375192878
2781998501
3180235862
3558688661
3979967708
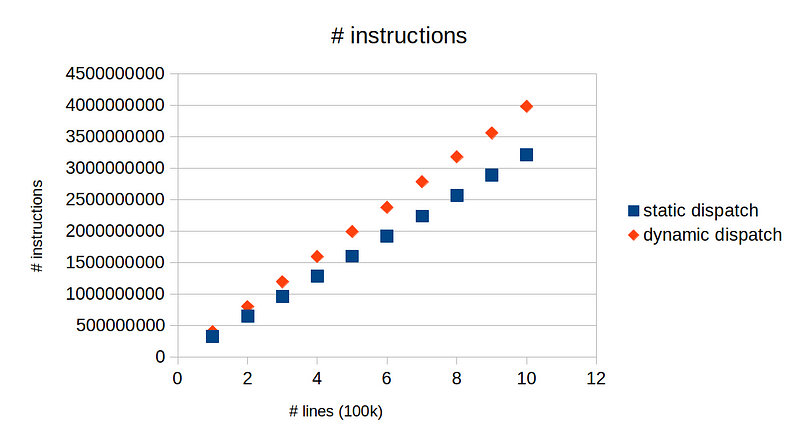
Here, for each n in 1,2,…,10, the file input_n.tsv contains n*100k lines of text. Below is a plot of the results above.
We can clearly see that static dispatch requires fewer instructions. In general, fewer instructions translate to more efficient program provided all other conditions being equal. We can also measure the runtime difference of the two:
for n in `seq 10`; do /usr/bin/time -v ./target/release/ntokens --dispatch static --delimiter tab input_$n.tsv 2>&1 | grep wall | gawk '{print $8}' | cut -f2 -d: ; done
00.05
00.10
00.13
00.18
00.22
00.26
00.31
00.36
00.38
00.44
for n in `seq 10`; do /usr/bin/time -v ./target/release/ntokens --dispatch dynamic --delimiter tab input_$n.tsv 2>&1 | grep wall | gawk '{print $8}' | cut -f2 -d: ; done
00.04
00.11
00.15
00.20
00.24
00.31
00.35
00.39
00.42
00.50
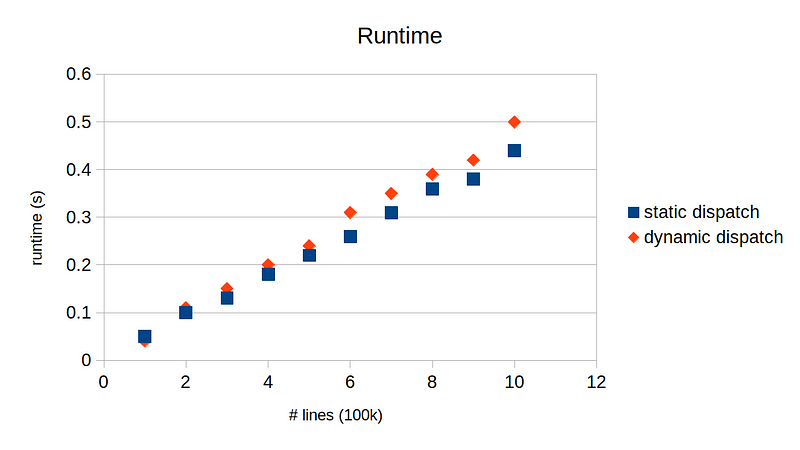
Apparently, the runtime measurements fluctuate a lot and do not exhibit as clear linear trend as the # instructions, but we can still observe that the static dispatch implementation tends to run slightly faster than the dynamic dispatch implementation. Obviously the runtime performance will also depend on many other factors, so it is best to test your own version yourself.
So, where does the overhead come from? Typically dynamic dispatch alone should not incur much overhead — only a few extra instructions to look up the v-table. The majority of overhead, at least in this particular program, comes from elsewhere: creating a Boxed iterator for each line. Depending on the delimiter option, we use split or split_whitespace method, each returning a concrete iterator. In the static dispatch case, we call count method on the concrete iterator itself, so there is no need to Box the iterator. With dynamic dispatch, we invoke tokenize method that returns a Boxed iterator for every line of the input. This is the major overhead — instantiating the iterator object in the heap for every line. Then of course, there is the actual dynamic dispatch happening when we invoke count method on the Boxed iterator object, but this shouldn’t cost too much.
Well then, why do we bother to Box the iterator? Because of flexibility in design. Rust is a statically typed language. Every variable’s type should be known at compile time. Because split and split_whitespace methods return different types, i.e., Split struct and SplitWhitespace struct respectively, we cannot have a single variable assigned to two different types interchangeably at runtime. But what we can do is to Box the iterator so that we have a common trait object, whose concrete type is hidden from the compiler. That is why we can assign two type-incompatible functions to a single variable tokenize, which provides much flexibility in the design, at the expense of extra runtime overhead.
So, the trade off between static vs dynamic dispatch really comes down to runtime performance vs design flexibility.
The source code is available here.